前面讲了双塔模型召回,这一篇讲万能的双塔模型做排序,在广告和推荐的粗排序环节广泛实用。
双塔排序
首先这里的排序指的是粗排环节,召回侧多个召回渠道可能会召回几千级别的item,而精排模型一般复杂度比较高,所以整体目的是从几千的用户可能感兴趣的item里选出用户最感兴趣的top几百。
而样本侧呢,也没什么可说的,就直接用精排侧落的样本,比如点击率模型的话,就是曝光点击为正样本,曝光未点击为负样本。
两侧塔分别对应user塔和item塔,这里可以用一些在精排环节重要性比较高,有区分度及比较复杂的特征,因为整体来说这个量级计算量能hold住,特征做好了就可以训练模型。
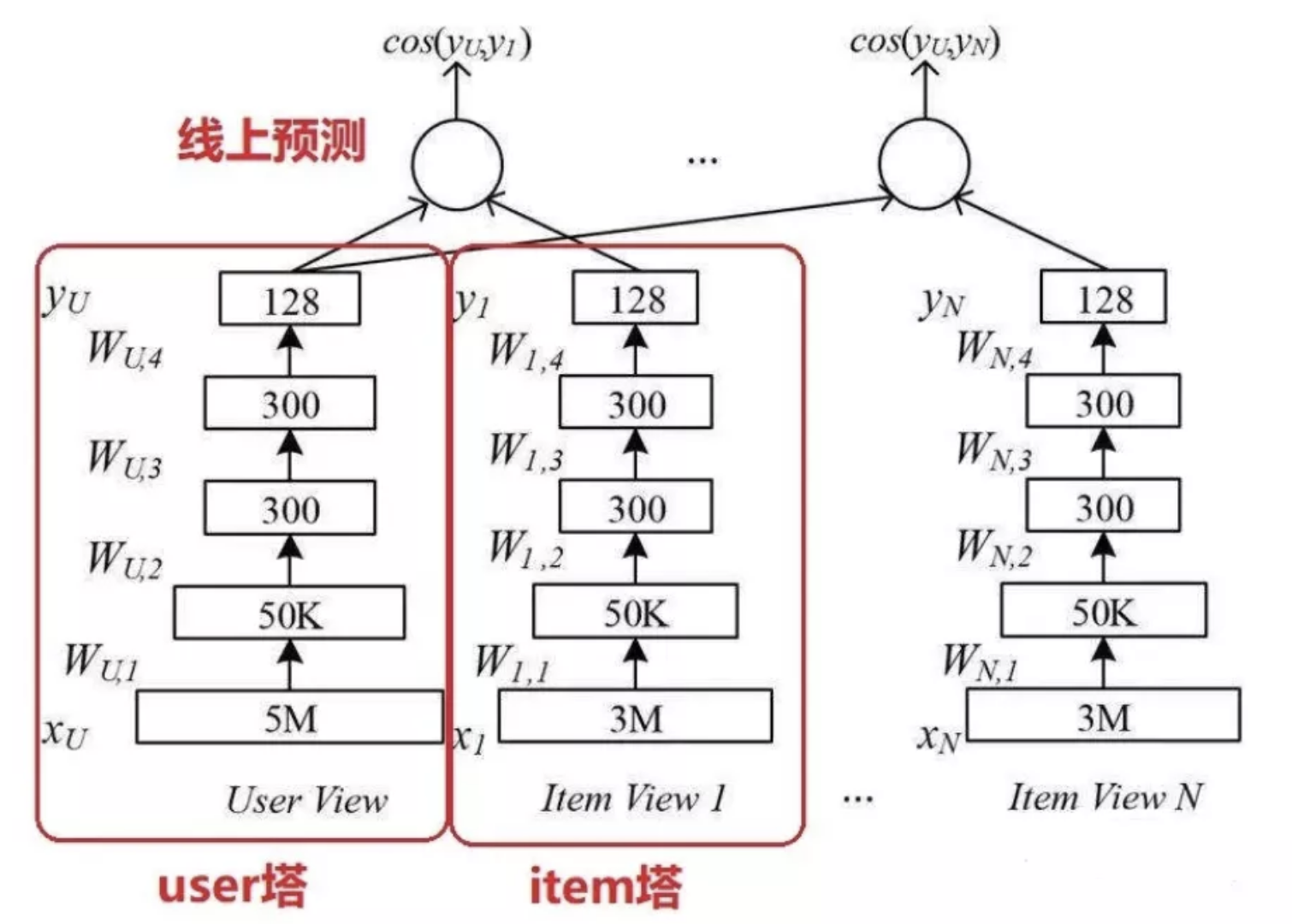
线上依然是一样,所有item预测缓存起来,等到线上请求来了之后只预测user侧embedding,然后计算和缓存item的相似度排序即可。
ESMM粗排多目标
对于漏斗型转化场景来说,比如电商点击、购买的转化漏斗,基础的方案是点击和转化分别训练相应的模型,线上通过预估服务后去分别预测\(P_{ctr}\)和\(P_{cvr}\),然后加权融合去推荐。
这样做有两个比较大的问题,首先正常客户转化是很稀疏的,比如我们拿到的某海淘客户从曝光到转化是万分之几的转化率,而点击正常时百分之几,所以相对转化很稀疏;另外需要考虑,点击模型学习到的东西是否是对转化模型有帮助的,比如客户最近疯狂浏览各种手机,那么这个信息对预测客户是否会购买手机有帮助,肯定是有的。
针对这些情况,阿里提出ESMM模型《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》,我们借鉴他的思路,分别搞两个双塔模型,左侧双塔学习点击率,右侧双塔学习转化率。
训练对时候点击且购买了,则左侧塔的label为1,且最终的label也为1,点击未购买,最终的label变为0,剩下曝光未点击的两个都为0,右侧塔的相似度是自由的,让模型自己去学习。
上线后一样获取user点击和转化的各自embedding,然后分别和需要排序的商品计算最终购买率score,去做排序。
他的优点是线上预估性能很好,因为只要计算相似度就可以,效果也还可以,是商品多目标场景粗排环节的不二之选。
其他疑问
既然召回和粗排都用双塔模型,那么为什么要搞这么复杂?我直接搞一个模型做整个召回和粗排的事情是否可以呢?
答案是不可以,这个要分广告和推荐单独来说,在广告里面,召回环节不单是是单纯的match,还要考虑关联性,比如搜索宝马,如果不考虑关联性很可能会关联出来点击率很高的热门广告,所以要早召回dssm模型里面做很多约束关联性的事情,百度Mobius就是做这个事情;那么出了这种关联性之外,再推荐里面是否可以呢,答案也是最好不要,原因是召回和粗排的目标不一样,召回因为要从整个物料集里面选出来可能喜欢的,正常物料集会很大,可能是千万甚至亿级别的,那么对检索的性能要求会很高,也就是说模型的维度和复杂度不能做的很高,但是粗排是从几千里面选出top几百,只要对几千做打分就可以,那么就可以做准确度更高参数更大的模型。整体分开做的好处有以下几点:
- 模型可以做的更复杂,准确度更高
- 样本侧可以单独做,各自的样本应对各自的目标以及分布
- 粗排可以直接计算相似度,而不用通过faiss之类的模糊检索,匹配度更准确。
- 对于像广告这种的,还会涉及到和query的关联性,所以召回需要单独的优化