今年和带的实习生一起做了下双塔模型,一方面这个模型在工业界的大量运用,另一方面他符合我的审美大的道理都是最简单的道理,实用的模型也是结构上很简洁的模型。所以打算写关于双塔模型的一个系列的文章,双塔召回、双塔排序、双塔多目标、以及塔的结构上的改进。
模型介绍
双塔模型最早是2013年微软提出,《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》,主要是解决搜索中query和doc之间匹配的问题,后来发现这个思路正好和推荐召回环节的思路完全一样,所以就借鉴给了推荐,当然国内用的最早的是百度2015年用它来做广告的召回,我认为本质上和推荐的召回是一样的,都是要召回去用户可能会喜欢的item,基本网络结构是这样。
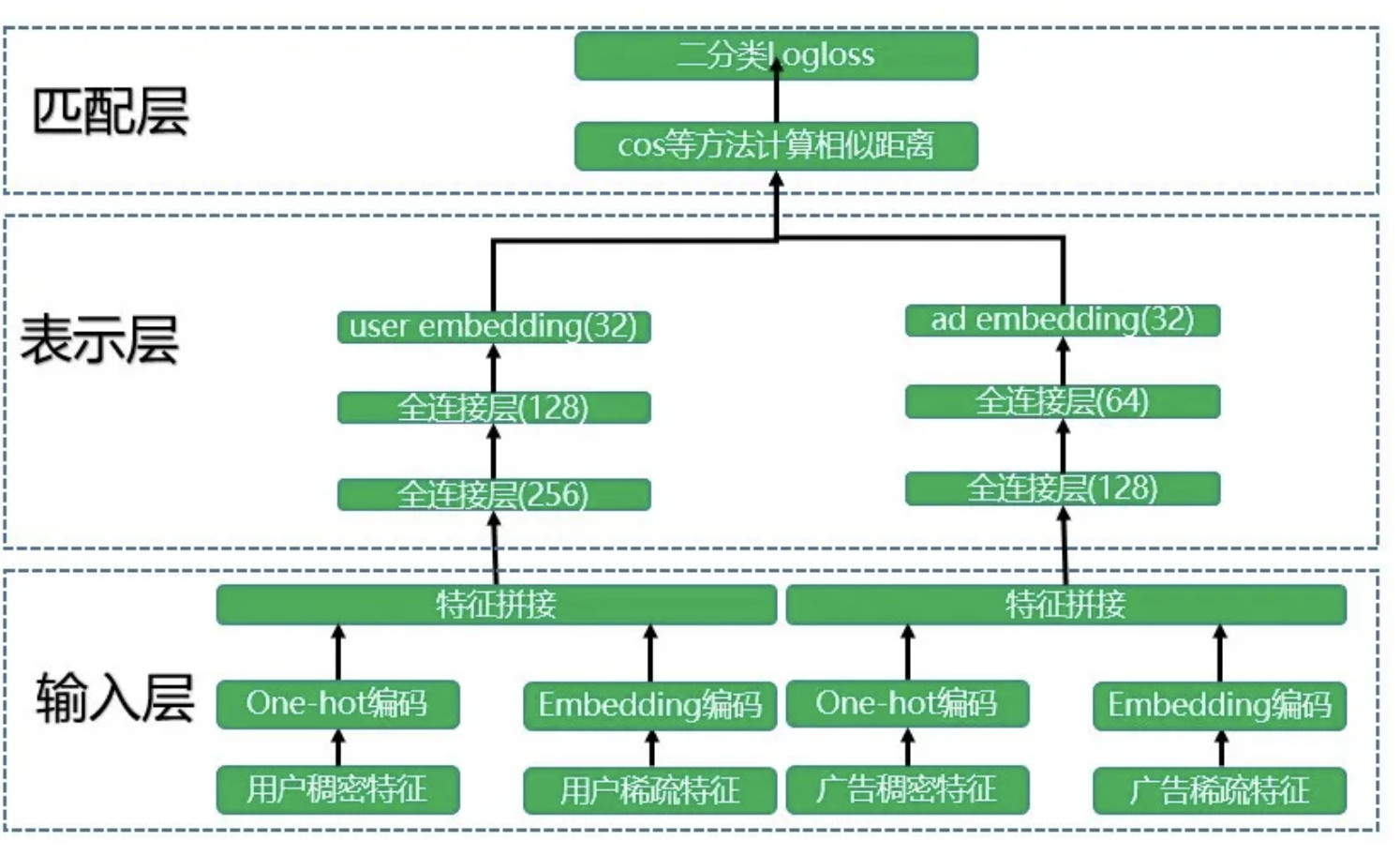
整体模型为两个塔,一侧是user一侧是item,这也是双塔模型的由来。
模型简单可以分为三层,最下面输入层,会直接数据训练样本特征,中间dnn维表示层,相当于对user和item侧学习各自的表示,最上层为匹配层,也就是最终输出,求匹配度的。
整体模型是个有监督模型,训练样本需要确定正负样本,对于召回模型来说,即那些是用户感兴趣的item,那些是用户不感兴趣的item,各自为正负样本。
双塔召回
模型就是上图所示,当我们拿到一份训练样本之后,很简单就可以train出来一个简单的模型,拿到模型之后我们就要上线用了。其实也比较简单,先对整体item做一次整体预估,拿到item塔侧所有item的embedding集合,然后线上来了用户请求之后,对当前user走一遍左侧user塔的预估,拿到当前用户的最新embedding,和我们之前保存好的item的embedding集合做一次向量相似度计算,然后拿到匹配度最高的topN,作为这一次的召回结果。
正常来说我们应该对于所有的item都应该走一次预估,但是考虑到item需要每次预估所有的,正常来说总量会很大,而且item的embedding如果训练样本够充分的话,其他短时间内变化是比较小的,所以就牺牲小小的效果,换来大大的性能。整体把item的embedding侧缓存起来,当然这里面求向量相似度可以用向量检索工具,比如spotify的annoy或者facebook的faiss,基本上性能都很好。
性能问题解决了之后,还是要回来考虑效果,那么item侧什么时候更新呢,常用的做法是,当有新的训练样本产生时,追加训练模型,同时对于追加的数据中的所有item重新预估embedding,更新到检索索引中去,这样就能保证模型是实时更新,item embedding也是最新的,而且性能很好。
典型优化
双塔召回或者说召回问题,最典型的就是样本的定义,如果按照我们往常思路来说,在排序的时候落特征,然后等到端上收到用户反馈,拼上label,就得到了训练样本,这个训练样本的含义是,给当前user推荐了10个item,他点击了其中两个为正样本。
正常我们可能会直接把这个样本拿过来训练,他的问题是什么呢?正样本肯定没有问题,他点击率必然是他喜欢的,但是他没有点击的就一定是他不感兴趣的嘛,如果是不感兴趣的那为什么模型召回而且排序排到了前面呢?
我们把所有的样本分成三类,最上面是推荐且点击了的,一定是最感兴趣的,甚至可以说是喜欢的,中间一层就是推荐了,但是没有点击的,其中必然大部分是客户感兴趣的,最后一部分就是没有推荐过的,这部分大概率是用户不感兴趣的。所以能想到最简单的思路就是正样本依然不变,负样本变成第三部分,即没有推荐过的。
从逻辑上分析这样很完美,但是操作一下会马上发现会遇到一个问题,就是对于模型来说这个问题太简单了,二分类模型要解决的问题就是在空间中划一条线或者一个面,把正负样本隔开,但是我们这样设计样本,这个中间间隔本身就很大,模型很容易就隔开了,对于模型来说太简单了,就会导致什么问题呢?模型学习到的用户兴趣太粗了,比如学习到了用户喜欢体育不喜欢口红,但是不知道这个用户喜欢的是nba,其他的足球高尔夫其实不喜欢的,更进一步用户其实喜欢詹姆斯,其他球星杜兰特这个用户无感,甚至有的是讨厌的,这就是模型学到的太粗了。
增加准确性
基于上面提到的问题,能想到的简单思路就是,那就给他增加点难度,给一些和他喜欢的样本相似的样本的,但是他并不喜欢的。
假设我现在有一个上帝模型,这个上帝模型能够完全准确预测任何用户对任何物料的喜欢程度,那么我用上帝模型给当前用户排序,拿到topN,我可以选择中间部分的作为Hard Negative,比如N为1000,那么我可以选100-500,作为Hard Negative,这部分相比前top100,用户对他的感兴趣程度低,但是相比其他的,其中又有一些点是用户感兴趣的,这样就能增加模型的眼界。当然在推荐系统中最接近上帝模型的就是精排模型,所以我们可以先离线用精排模型过一遍。
当然还有一种方法是用曝光未点击的当作Hard Negative,facebook论文《Embedding-based Retrieval in Facebook Search》实验效果不好,另外Hard Negative和普通负样本的比例,这篇论文也给出了建议1:500,普通负样本负责让模型见世面、而Hard Negative负责让模型开眼界。