现在常用的有两种建模思路,要么是用简单的模型和复杂的特征工程,要么是用复杂的模型和简单的特征工程,相当于你喜欢玩模型还是喜欢玩特征,各自有各自的好处,当然玩特征可解释性好以及要求比较低。而玩特征大家最多用的模型就是罗辑回归,这里记录一下用逻辑回归建模的历程以及优化思路。
首先我用的是线上4天的数据集,总计2000w数据,先把数据按照请求时间(action_show_actionTime)排序,然后前1000w用做训练数据,后1000w用作测试数据,当然也可以7-3分,经测试效果差距不大,其中评估指标主要用AUC和group AUC,group的key是userId。
首先对于所有离散特征直接one-hot,对于所有连续特征直接continuous处理。
#user
f_userId = discrete(userId)
f_user_interest_channel = discrete(splitbykey(user_interest_channel, ",", ":"))
f_user_interest_tag = discrete(splitbykey(user_interest_tag, ",", ":"))
#item
f_item_id = discrete(item_id)
f_title_parent_id = discrete(title_parent_id)
f_item_4pd_show_cnt = continuous(item_4pd_show_cnt)
f_item_4pd_click_cnt = continuous(item_4pd_click_cnt)
f_item_item_read_cnt=continuous(item_read_cnt)
f_bonus = continuous(bonus)
f_publish_time = discrete(publish_time)
f_publisher_id = discrete(publisher_id)
f_category_v1 = discrete(category_v1)
f_tag = discrete(split(tag, ";", "string"))
#env
f_channel = discrete(channel)
f_logWriteTimeHuman = discrete(logWriteTimeHuman)
这里需要说下,特征分为三类,用户特征,物品特征,以及环境特征,而环境特征中logWriteTimeHuman可以当作是请求时间,这里训练先用这个后续预估会做替换。
直接用这些特征,LR默认参数的情况下AUC为0.56,算是挺低的了,因为0.5就相当于瞎猜,就是比瞎猜稍微好点。
连续特征分桶
因为LR适合处理离散特征,所以我们对物品的两个重要特征做一下等频分桶,先选两个物品最主要特征show和click。
f_item_4pd_show_cnt=discrete(bucketize(item_4pd_show_cnt, "0.0", "3397411.0", "10 100 1000 10000 100000 1000000", "1.0E-8"))
f_item_4pd_click_cnt=discrete(bucketize(item_4pd_click_cnt, "0.0", "337164.0", "10 100 1000 10000 100000", "1.0E-8"))
分桶后AUC提升为0.626,提升挺明显的,说明物品的热度信息对于用户的点击率影响很大,更热的物品用户点击的概率更大。
加入二次计算特征
前面我们分析,物品有热度信息,对于我们预测影响很大,那么我们猜测是否用户也有类似的性质,不同深度的用户的点击是否一样呢。
select *, size(split(user_interest_itemId, ',')) as user_4pd_click_count,item_4pd_click_cnt/item_4pd_show_cnt as 4pd_ctr,pmod(datediff(logWriteTimeHuman, "2018-01-01"), 7) as action_week from t1
这里主要算了三个特征,一个是计算用户最近点击的物品数据数目,物品的ctr,以及请求是周几。
加入第一个用户点击物品数后,AUC提升到0.691,第二个物品ctr特征加入,AUC继续提升到0.695,第三个星期几特征加入,AUC提升到0.699
f_user_4pd_click_count=discrete(bucketize(user_4pd_click_count, "0.0", "34.0", "2 5 10 15 20 30", "1.0E-8"))
f_item_4pd_ctr = discrete(bucketize(4pd_ctr, "0.0", "1.0", "10 100 1000 10000 100000", "1.0E-8"))
f_action_week = discrete(action_week)
基本上可以看出来,这三个二次计算特征的作用是很大的,直接把AUC提升了7个百分点,其中尤其第一个特征最明显,当然也比较好解释,就是这份数据新老用户的点击率差异很大,或者说某一部分的用户点击倾向相比其他很明显,物品的点击率同样客户物品的冷热程度,最后星期几,说明每周的不同天里面,存在一定趋势在某些天更倾向点击。
组合特征
没有组合特征的LR不是个性化的,所以我们尝试对特征进行组合。
组合特征的思路一般是把用户、物品、环境三个维度中选两个维度的重要特征做组合,当然也可以三个维度组合,甚至不排除非重要特征组合后效果比较好,下面是我的一些组合特征,主要是用特征重要性高的不同维度的特征进行组合。
#conbine
combine_userId_action_hour=discrete(combine(userId,hour(logWriteTimeHuman)))
combine_userId_channel=discrete(combine(userId,channel))
##combine_userId_publisherId=discrete(combine(userId,publisher_id))
combine_userId_itemShowCnt = discrete(combine(userId,bucketize(item_4pd_show_cnt, "0.0", "3397411.0", "10 100 1000 10000 100000", "1.0E-8")))
combine_userId_itemCtr = discrete(combine(userId, bucketize(4pd_ctr, "0.0", "1.0", "10 100 1000 10000 100000", "1.0E-8")))
combine_userInterestTags_itemTag=discrete(combine(splitbykey(user_interest_tag, ",", ":"),split(tag, ";", "string")))
combine_userInterestCategoryV1_itemCategory=discrete(combine(splitbykey(user_interest_category_v1, ",", ":"),category_v1))
combine_userInterestChannel_channel=discrete(combine(splitbykey(user_interest_channel, ",", ":"),channel))
#combine_userClickCnt_itemShowCnt = discrete(combine(bucketize(user_4pd_click_count, "0.0", "34.0", "2 5 10 15 20 30", "1.0E-8"), bucketize(item_4pd_show_cnt, "0.0", "3397411.0", "10 100 1000 10000 100000 1000000", "1.0E-8")))
combine_itemId_channel=discrete(combine(item_id,channel))
#combine_itemTag_channel=discrete(combine(split(tag, ";", "string"),channel))
combine_itemId_actionHour=discrete(combine(item_id, hour(logWriteTimeHuman)))
combine_itemId_userClickCnt = discrete(combine(item_id, bucketize(user_4pd_click_count, "0.0", "34.0", "2 5 10 15 20 30", "1.0E-8")))
combine_userId_itemCtr_actionHour = discrete(combine(userId, bucketize(4pd_ctr, "0.0", "1.0", "10 100 1000 10000 100000", "1.0E-8"), hour(logWriteTimeHuman)))
组合如上,其中注释掉的是组合后特征重要性低的一些特征。组合后AUC为0.703,虽然AUC提升不多,只有4个千分点,但是模型泛化能力以及个性化提升了不少,其中有很多组合特征的重要性很高,但是为什么AUC没有提升呢,目测已经接近这份数据的AUC上限了,什么是AUC的上限可以参考我直接对AUC指标分析对文章。
数据采样
采样常用的方法是对user做采样和对item做采样,因为之前userAUC一直是0.514左右,比较低,所以考虑为了提升userAUC对数据做用户采样,第一次首先对用户样本数大于10条的数据做采样,共计1387w。结果AUC为0.683,userAUC为0.534,第二次对用户样本数大于30条的数据做采样,采样后数据拥挤917w,结果AUC为0.686,userAUC为0.545。
可见采样后userAUC确实有提升,但是AUC有下降,这个下降是两方面原因,一个是我们采样一般只对训练数据做采样,测试数据还是用原数据;另一方面采样后数据量减少了,但是特征维度变化不大,所以可能会导致欠拟合。
但是最终效果怎么还需要线上验证,不一定线下AUC高线上点击率就一定高,分析线下和线上表现关系也是模型很重要的一块。
调参数
| 训练轮数 | L1 | L2 | 训练AUC | 测试AUC |
|---|---|---|---|---|
| 4 | 0 | 0 | 0.83 | 0.703 |
| 4 | 4 | 22 | 0.8 | 0.704 |
| 4 | 5 | 28 | 0.788 | 0.704 |
| 4 | 5 | 35 | 0.786 | 0.704 |
| 4 | 10 | 35 | 0.763 | 0.705 |
| 5 | 15 | 35 | 0.763 | 0.705 |
另外对训练和测试数据由原来的5-5分修改7-3分之后AUC从0.705提升到0.708.
总结
这里是特征重要性以及模型评估。
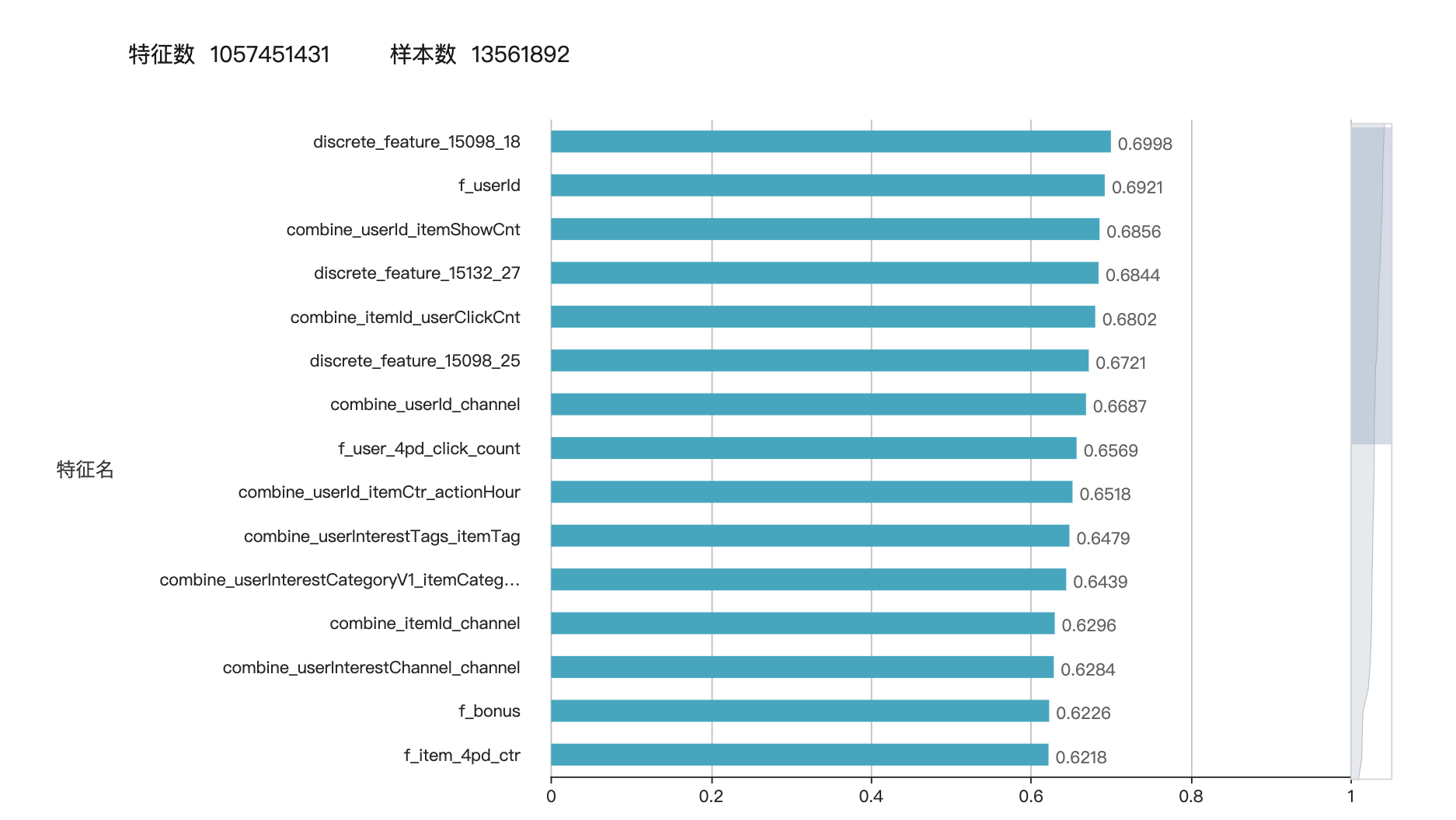
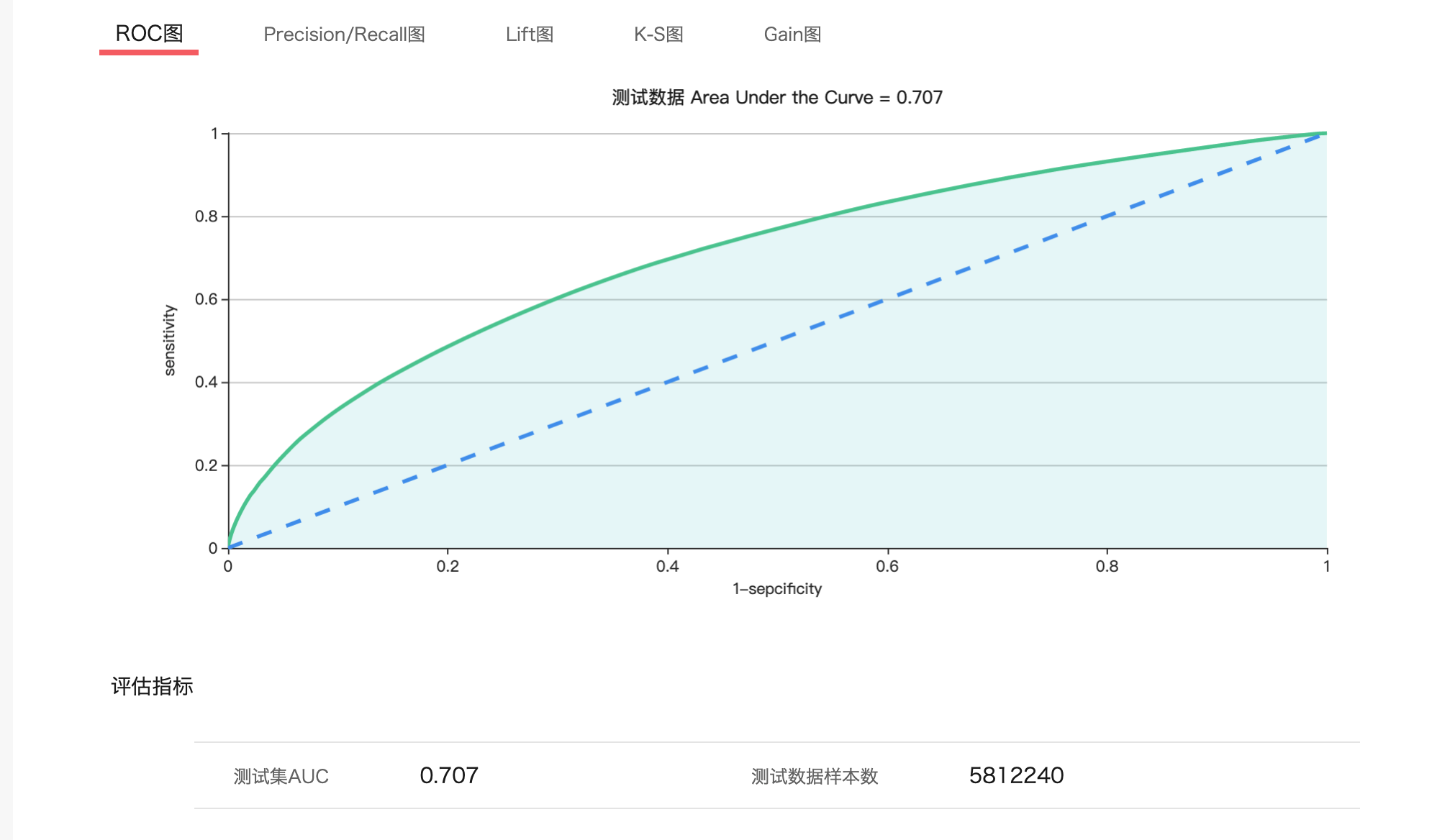
基本上就是这样,特征工程往细了做还是有很多可以做的地方,后续主要发力方向是通用特征,以及AUC和线上点击率的DEBUG,AUC提升是否点击率也会提升或者相同数据是否AUC高的意味着点击率就一定高。最近正在分析这样一个问题,有机会在写一篇。