背景
在电商推荐中,用户兴趣的建模是一个非常重要的点,现在电商的主流厂的方向也都是在往这个方向发力,其中阿里妈妈是走在前沿的,从18年开始陆续提出了DIN、DIEN、MIND、SIM。
用户兴趣建模最早是用用户画像,在底层会有专门的人来做用户画像,上层的模型在使用建立好的用户画像,他的好处是做出来的东西可解释性比较好,人类易读,但是缺点同样也很明显,就是建立画像和使用画像是两个部分,前后形不成反馈,各自做各自的事情,对上层来说,如果你做的画像好,我就用上,不好我就舍弃了,我没办法去改进他;下层的人也是摸黑做,做完没有显示的评估方式,做机器学习最怕的就是没有明确的label。
所以现在基本上画像和模型用户兴趣刻画分开了,画像负责做画像的事情:,模型的兴趣刻画由模型测自己负责,这样可以有监督的端到端优化。
这其中兴趣刻画从最早的DIN,用户行为序列从最开始的Simple Average Pooling到通过使用待预估商品的embedding和行为序列中embeeding求相似度作为权重加权Pooling。到后面DIEN中又通过在网络中自底层向上依次定义了行为序列层、兴趣抽取层、兴趣进化层,关键在一兴趣抽取和兴趣进化,这里使用了一些NLP中的GRU单元并引入attention,从而引入行为序列的时间信息更深刻的刻画用户兴趣,服务于模型。到MIND又提出了基于记忆网络的模型,后面有机会在这个系列里面都讲一遍。
从另一个角度来说,从DIN一路走来,模型能捕获的用户行为序列也越来越长,这四个模型分别能捕获的行为序列长度为十、百、千、万,模型学习的信息越充足,则模型的判别能力越强。
模型
原始模型是阿里20年发在arXiv上https://arxiv.org/abs/2006.05639,读下来感觉整体是一种用户行为序列的编码方式,所以做电商的童鞋都可以在记得主线模型上加入这个处理方式试试。
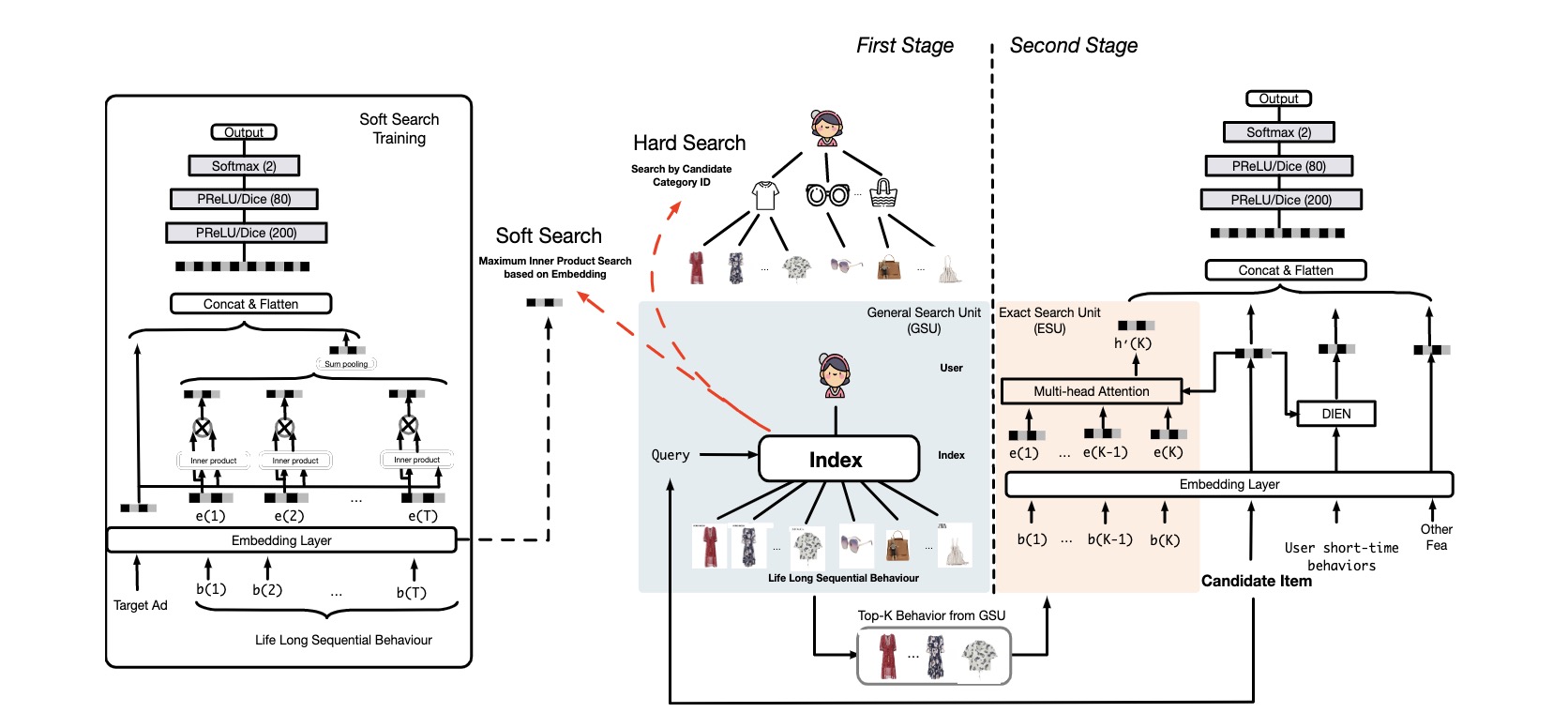
基本上模型入上图所示,按照虚线分为左右两部分,左边是兴趣检索模块,右边是排序模型结果,其中本论文核心的是颜色框出来的两部分,蓝色部分就是叫做GSU,橙色部分叫做ESU。
General Search Unit
这部分又分为两种方式,即soft search和hard search,先说简单的hard search,简单说就是找到用户行为序列中和当前预估商品分类一样的商品,比如当前要预测的是一件连衣裙,那么hard search中得到的结果是你历史行为序列中所有的连衣裙作为输入。表示为:
\[r_i = Sign(C_i = C_a)\]其中\(r_i\)是待预估商品和行为序列中商品的相关性得分,\(C_a\)待预估商品商品的category,\(C_i\)就是行为序列中的第i个商品的category,即类目相同就认为相关。
而soft search部分,首先需要得到商品的embedding表示\(e_i\),即需要一个预训练的过程,如上面图中左侧部分表示所示,得到预训练embedding之后,表示为:
\[r_i = (W_b · e_i) · (W_a · e_a)^T\]其中\(W_b\)和\(W_a\)是模型参数,\(e_a\)表示待预估商品的embedding,\(e_i\)是用户行为序列中商品embedding,当训练完成参数得到之后,线上可以使用向量检索系统求TopK加速。
Exact Search Unit
通过第一步,我们获得了每个待预测商品的最相关用户行为序列\(E^*\),同时还有一个很重要的是用户发生行为的时间信息,本文是计算历史行为发生时刻距离当前预测商品的时间差,通过embedding表示为\(E_t\),通过对这两部分拼接成\(z_j = concat(e_j^*,e_j^t)\),然后使用一个multi-head attention结果来捕捉行为序列中的信息。
\[att_{score}^i = Softmax(W_{bi} z_b · W_{ai} e_a)\] \[head_i = att_{score}^{i} z_b\]实验结果
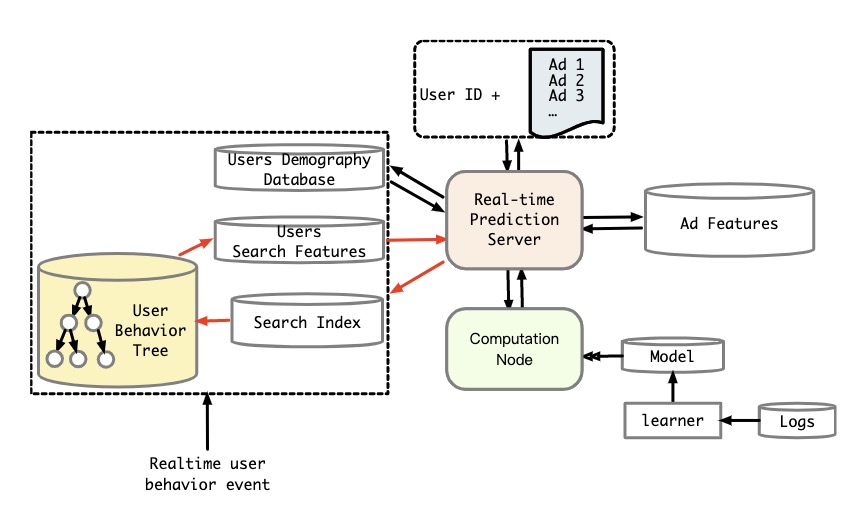
在阿里的实验中,soft search中检索的结果和hard search中获得用户行为序列非常相似,从最终效果上来说效果是微微好于hard search的,但是从性能角度两个差异很大,所以阿里线上是直接使用hard search的方式,如图所示线上是通过缓存来存储,构建方式为key1->key2->value的形式,其中key1是userId,key2为category,value就是该类目下行为序列。
实验是通过淘宝和亚马逊的公开数据集以及阿里妈妈真是广告场景的样本实验,观测指标是AUC,第一次是直接对比,其中为了验证长期兴趣的影响加入了Avg-Pooling Long DIN,直接把长期行为序列Pooling之后放入DIN,结果如下。

首先看到的是长期兴趣是有效的,Avg-Pooling Long DIN对比单纯DIN提升1.7个点,SIM是明显好于其他的,加入时间信息的SIM也带来了一个点的提升。第二次实验是直接把两阶段拆开看看对最终结果的影响。
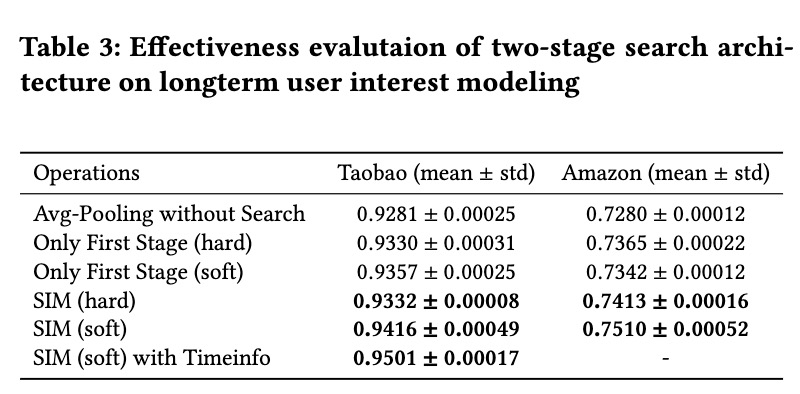
可以看到引入了用户长期兴趣就能带来提升。
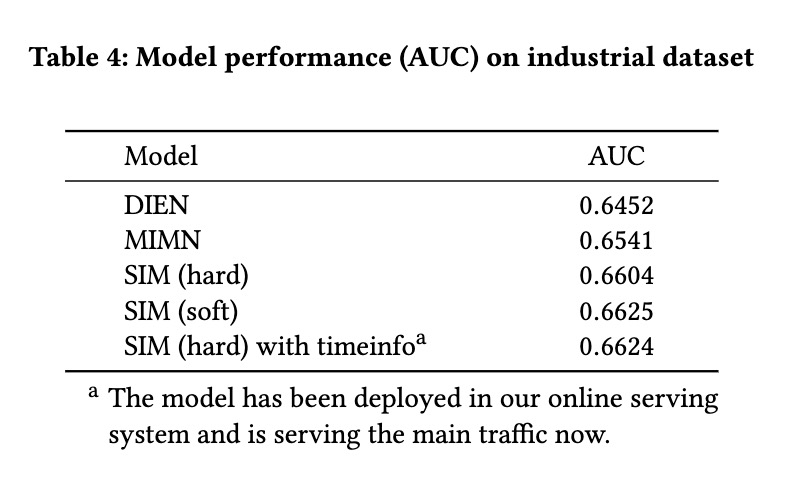
下面是在阿里妈妈真实场景上的结果,基本上引入SIM之后相比之前最好MINE带来0.8个AUC的提升,同时在线上广告猜你喜欢场景,SIM 相比在线主流量模型得到了显著提升CTR+7.1%, RPM+4.4%。
总结
虽然论文看着很复杂,其实总体思路还是很简单的,就是在用户行为序列中引入用户历史上所有的兴趣,引入的时候为了计算量每条样本筛选出和当前打分物品相关的子序列,比如在商品中直接选择相同category的就很不错。
第二个是使用Transformer中的multi-head attention来编码用户行为序列,这个其实也不算什么独创。
总体来说是一个很好的思路,因为在推荐中历史上所有的行为序列中包含的信息的使用一直是一个难点,之前尝试这个方法在短视频推荐上也能拿到很好的收益,所以看到的话就在你的线上模型中试试。