再上一篇MMOE中遗留下来一个问题,在多阶段多目标优化中,后面阶段转化必然要在前一阶段转化成功的基础上产生的,这两阶段的关系怎么建模到模型中,看看ESMM是怎么解决的。
ESMM原始论文是阿里2018年发在SIGIR上面,《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》,主要解决了两个问题,一个是上面提到的多阶段信息损失问题,另一个是后面阶段正样本偏少的问题,本质其实是一个问题。
模型背景
现在有一个电商场景位,运营说今年整体指标是GMV提升10%,从运营的角度可以拆解成客单价 x 成交订单数,这两个在算法的角度都是没法直接优化的,算法的角度是有一个推荐位用户每次来我可以给他曝光他最想买的商品,如果我把从曝光到转化的概率提升10%,那是不是可以完成目标了。
这里涉及到一个转化漏斗,我们简化为给用户曝光 -> 用户点击 -> 用户购买,中间有两个转化状态,假设我们把整个转化率叫做\(P_{ctcvr}\),涉及到模型上就是要预测用户对当前商品点击率\(P_{ctr}\),和假设点击之后产生的转化率\(P_{cvr}\),则公式定义为
\[P_{ctcvr} = P_{cvr} · P_{ctr}\]对应到我们离线收集到的样本上,特征假设为x,点击假设为y,购买假设为z,转化后就是
\[P(y\&z = 1 | x) = P(z = 1|y = 1,x) · P(y=1 | x)\]最终要预估的点击转化率对应样本就是购买的,点击率对应的是曝光后点击的,唯独中间转化率部分,我们根据公式定义可以看到前提是y = 1,即点击之后转化率,但是我们知道正常点击率是个10%不到,意味这大部分的样本没有产生点击,那么这部分的转化率就是个未知数,既然是未知数,对应到模型中就要是一个参数变量。
模型结构
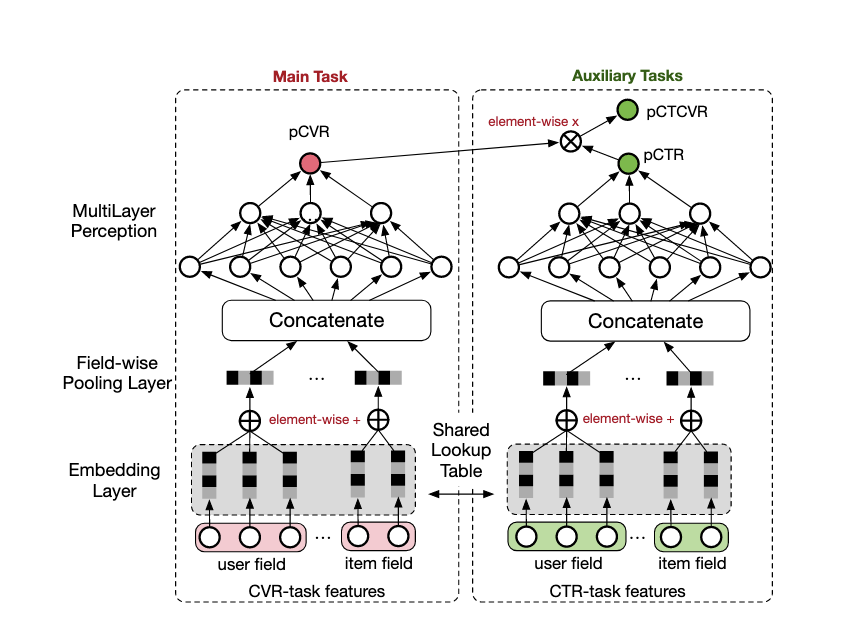
原论文中的网络结果如下图所示,底层是embedding是共享的,和MMOE的Shared-Bottom结构差不多,这里为了突出是两个模型画了两个单独的塔,在中间写上了Shared Lookup Table,表示是共享embedding的,到上面Concatenate之后才是单独的各自网络,基本上所有创新点都在左侧塔上面pCVR红色的节点上,这里的意思是这是个参数,会随着模型训练不断的持续迭代学习,而绿色的点是明确的label。
损失函数
在前面背景中说了,样本中label有两类,一类是点击,一类是转化,转化意味这点击且转化,则损失函数为:
\[L_(\theta_{cvr}, \theta_{ctr}) = \sum_{i=1}^N L(y_i, f(x_i,\theta_{ctr})) + L(y_i \& z_i, f(x_i,\theta_{ctr}) · f(x_i, \theta_{cvr}))\]利用label中的监督信息训练网络,前面部分是点击模型的损失,后面部分是整个的损失,即前面说的点击转化率的整体损失,想想这里为什么不用转化率。
总结
整体来说是个很简单的模型,给了我们一个对于多阶段有依赖关系的多目标优化一个很好的思路,核心点为:
- 对于依赖关系中,前一阶段发生后才能明确的信息,当作是参数而不是label去学,即上面模型中红色的点。
- 损失函数也是一样,监督学习label已经明确的部分,即点击率和整体点击转化率,未知的部分不做假设
通过网络结构和损失函数的巧妙设计,利用已知label信息迂回的学习了未知的CVR。当然这里只是一个思路,类似专利里面的一个点子,实际中根据实际业务和数据分布情况结合使用到自己的网络结构中就可以了,比如结合系列一中的MMOE增强学习能力,上面使用ESMM学习阶段转化信息。