19年Recsys上youtube出了两篇论文,虽然youtube中国推荐做的贼烂,但是论文依旧延续了精品的传统。
yougth这里对其中热度不是那么高的一篇《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》做一个精读。
总体思路
首先大体来讲,一个很有意思的点是,google也开始采用双塔召回了。至少从目前发的论文来看,没有在之前16年发布的论文NN结构基础上探索,那篇文章在之前的文章youtube深度学习推荐经典论文中关键点中分析过,而是采用了现在主流的双塔模型,双塔模型是在2013年微软发布的DSSM模型上发展来的,当初提出是为了文章检索设计的,双塔分别对应query和doc。现在推荐主流上用双塔都是user embedding塔和item embedding塔,总体结构如下图。
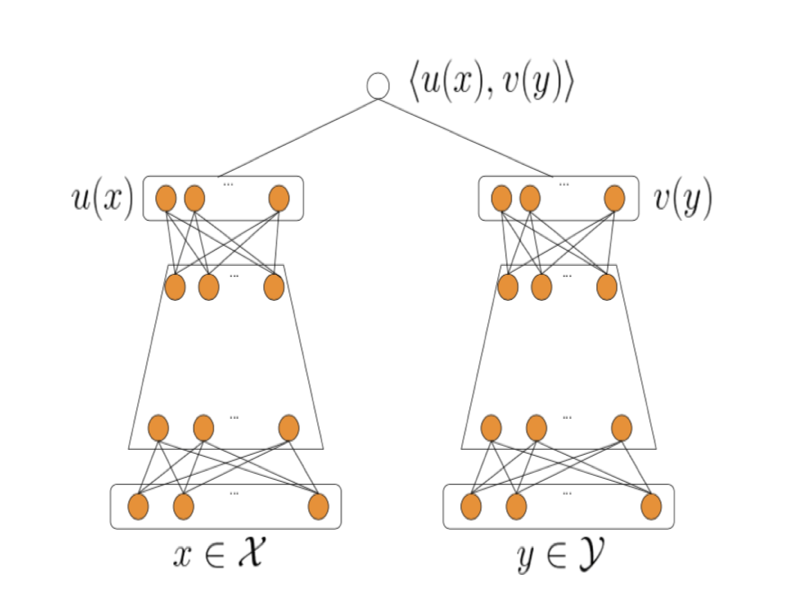
基本上结构很清晰,首先按照结构训练模型,模型训练好用图中的两个向量u(x)和v(y)求dot,对相似度高的item做推荐。其中两部分,左侧user塔后面的user embedding需要在请求来的时候实时计算,右侧item塔训练的时候预计算好,然后灌入一个向量检索工具中,首先建立索引,然后转化为一个向量检索问题,这方面基本做推荐的各家大公司都有自己的开源工具,比如faiss,annoy等。
核心问题
这里我们用x表示user和context特征,y表示item特征,\(\theta\)表示模型中的参数,则结果可以这样表示。
\[sim(x,y) = <u(x,\theta), v(y,\theta)>\]假设有T条训练样本,模型的目标是从这些训练样本中学习模型参数\(\theta\)。每一条训练样本定义为
\[\tau := {(x_i, y_i, r_i)}_{i=1}^T\]其中\(x_i\)表示用户特征和上下文特征,\(y_i\)表示物品特征,\(r_i\)表示每对样本的回报,比如文章的阅读时长,视频的播放比例等。那么这个问题可以认为是一个多分类问题,给一个用户x,从M个items的候选集\({\{y_j\}}_{j=1}^M\)中选择要推荐的item。多分类softmax函数定义为
\[\rho (y|x; \theta) = \frac{e^{s(x,y)}}{\sum_{j \in [M]} e^{s(x,y_j)}}\]定义对数似然函数
\[L_T(\theta) := -\frac{1}{T} \sum_{i \in [T]} r_i \dot log(\rho(y_i|x_i; \theta))\]接下来就是这个论文的第一个核心点了,在每个batch内,youtube的视频热度分布是符合幂律分布的,也就是热度效应是倍数关系,如果直接建模的话,就会导致推荐出来的东西比较偏热不够个性化,所以对相似度函数做这样的变形。
\[s^c(x_i,y_j) = s(x_i, y_j) - log(p_j)\]这里\(p_j\)表示视频j的采样频率,后面流式更新部分讲到。
具体推理直接贴上来,也比较直观。
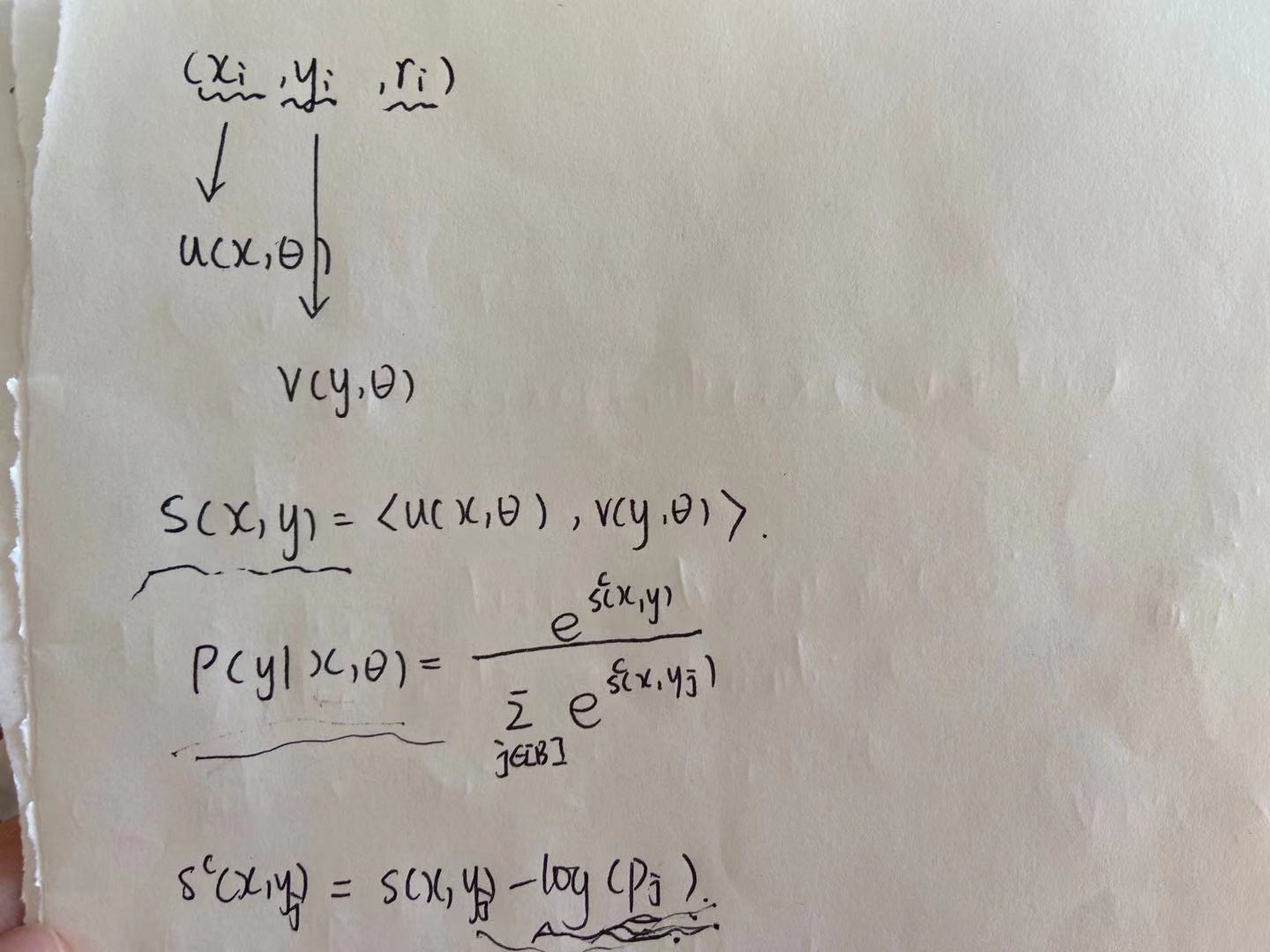
热度打压
通过前面,我们可以看到本质公式是这样的:
\[score = sigmod(dot(U_{emb},I_{emb}) - log(Hot(I)) )\]这里U和I分别表示user 和 item在双塔上面一层输出的embedding,而Hot(I)就是物品I的热度,即上面提到的P(i)。
首先我们看log函数是个什么样的函数:
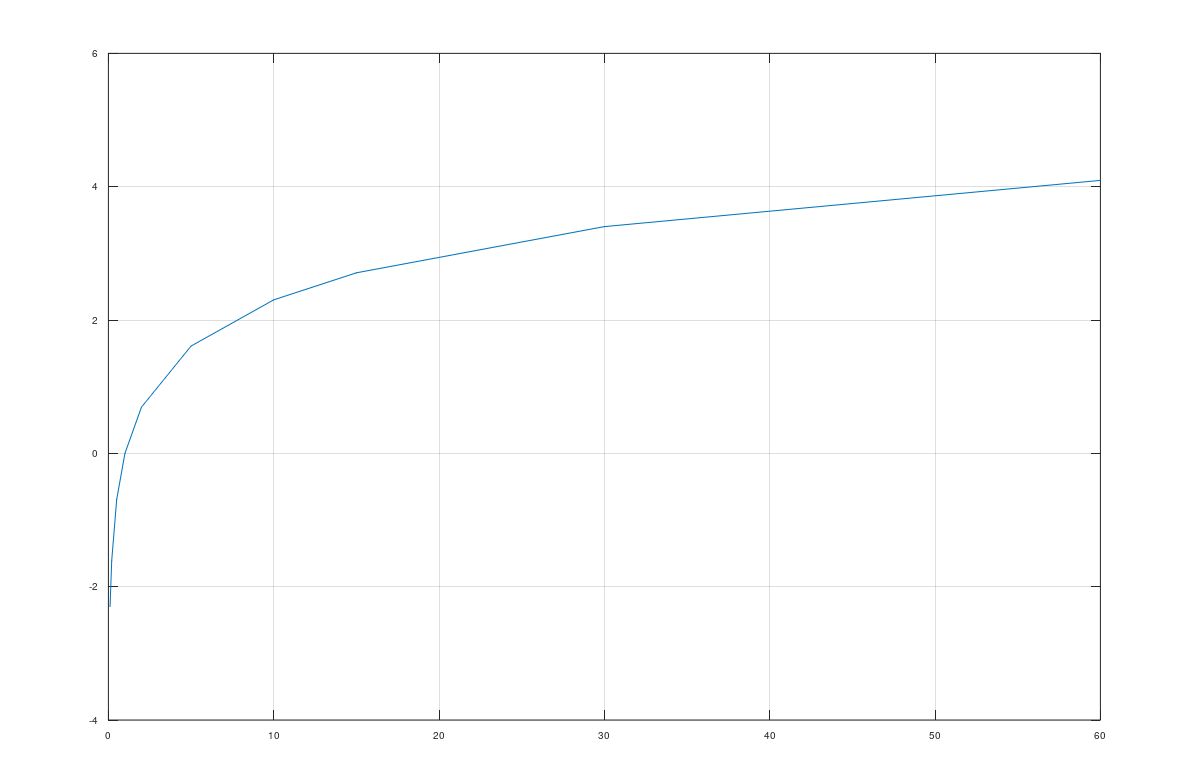
可以看到,它在横轴大于1的时候,y的取值开始为正数,且是个递增函数,关键是:前面部分我们说了,youtube的视频热度分布是幂律分布的,而log函数恰好是幂函数的反函数,也就是说它随着热度的增大,递增的趋势越来越小,意味着最热的视频和次热的视频可以差别是倍数关系,假设最热10^8,次热10^7,但是在log函数变换之后差值可能很小。
我们返回来看上面公式,对于一个热度比较高的视频,意味着模型需要把热度的部分也学习到双塔的参数中,在label固定的情况下,总是在双塔相似度后面减去热度的部分,相当于去除掉热度的bias。对于正样本来说,你观看了这个热的视频,那么很有可能你是因为视频热才观看的,所以要减去这个bias;对于负样本,你没有观看这么热的一个视频,那说明是你真的不喜欢啊,所以我要减去这个bias,非常make sense吧!
当然这里后面减掉的并不是热度,论文中说的是采样频率,本质一样,另外有个点是要保证相似度部分和热度部分分布不能差异很大。
流式更新
这块就是第二个核心了,本质是设计一个算法维护更新\(p_j\),他的定义为
\[p_j = \frac{1}{B[j]}\]接下来就是怎么去维护B[j]了,如下面图中推导的,首先定义一个一个hash函数\(h(y)\),把所有视频都映射到[0,H)之间。这里hash一下是因为视频是动态的,随时都可能有新的视频进入系统,所以用hash函数映射一下固定住视频。
接着定义A,B两个数组
- \(A[h(y)]\):\(item_y\)上一次被采样的step
- \(B[h(y)]\):\(item_y\)平均多少个step被采样一次,即采样频率
这里B的定义可以看出,B越小,即在训练样本中采样到的概率很高,比如2,每两次就会被采样到一次,那么\(p_j\)会比较大,就代表比较热,根据核心点一公式,降权就越大。
接着就是更新了,公式就不再写一遍了,其中\(\alpha\)是个系数,越大则越快受最近几次采到的影响大,小的话更新比较慢但是稳定。
有了这块的计算,剩下的就是带入到损失函数\(L_B(\theta)\)中梯度下降求解的过程了。详细推导在下面

当然原始论文里还给出来了一个这种算法的分布式计算方法,这里就不细说了。
总结
本质上是在解决youtube热度过明显而个性化不足的问题,这也是个推荐里面的大问题,从第一代cf的时候都要些公式给热门物品降权,举个极端的例子,比如最热的一个物品,占了系统中所有流量中一半的曝光,那么模型正常学习就会给所有人把这个物品排出来,导致效应进一步加剧。从系统角度,不利于长期推荐生态,可能冷的而没被发现的优质物品长期出不来;从用户的角度也一样,用户真正喜欢的物品可能出不来或者压根系统里没见过。
另一方面这是个召回算法,这个效应在召回环节尤其要注意,因为本质召回的目的就是召可能会喜欢的,不求精而求全。
所以围绕着这个目的,首先从相似度定义上就直接做了热度降权,其次是设计了一套分布式算法能够流式更新它。