人生中有很多选择问题,当每天中午吃饭的时候,需要选择吃饭的餐馆,那么就面临一个选择,是选择熟悉的好吃的餐馆呢,还是冒风险选择一个没有尝试过的餐馆呢。同样的,推荐系统处处也面临着这样的选择,是推荐一个已经熟悉的点击率很高的物品呢,还是选择一个新的物品呢。这些都可以泛化成一个经典问题,多臂老虎机问题,也是一个研究很广的问题,这里介绍一些常用的bandit算法。
Topmpson sampling(汤普森采样)
- 假设每个臂是否产生收益,其背后有一个概率分布,产生收益的概率为 p。
- 我们不断地试验,去估计出一个置信度较高的 “概率 p 的概率分布” 就能近似解决这个问题了。
- 怎么能估计 “概率 p 的概率分布” 呢? 答案是假设概率 p 的概率分布符合 beta(wins, lose)分布,它有两个参数: wins, lose。
- 每个臂都维护一个 beta 分布的参数。每次试验后,选中一个臂,摇一下,有收益则该臂的 wins 增加 1,否则该臂的 lose 增加 1。
- 每次选择臂的方式是:用每个臂现有的 beta 分布产生一个随机数 b,选择所有臂产生的随机数中最大的那个臂去摇。
可以很简洁的用一行pyhton代码实现
import numpy as np
import pymc
N = 100
i = 0
win = [0 ,1, 3, 6, 10, 100]
trials = [0, 2, 5, 30, 21, 205]
while i<100:
choice = np.argmax(pymc.rbeta(1 + wins, 1 + trials - wins))
wins[choice] += 1
trials[choice] += 1
i += 1
这个算法中重要点的理解:
- 对rbeta,也就是选臂的过程,其实本质就是选赢率最高的,也可以理解点击率最高的\(ctr =\frac{click}{show}\)
- 当新来一条物料,会优先进行explor,因为根据公式,新来物料ctr = 1
- 当然beta分布中的两个参数可以根据先验知识去设置,比如物料平均点击率3%, 那么我可以设置beta分布参数\(\alpha = 3\),\(\beta = 97\),这样更贴近真实情况,可能更有效。
UCB算法(Upper Confidence Bound)
- 初始化:先对每一个臂都试一遍
- 按照如下公式计算每个臂的分数,然后选择分数最大的臂作为选择:
- 观察选择结果,更新\(t\)和\(T_{jt}\)。其中加号前面是这个臂到目前的收益均值,后面的叫做 bonus,本质上是均值的标准差,t 是目前的试验次数,\(T_{j,t}\)是这个臂被试次数。
这个算法中重要点的理解:
- 首先公式前面一项是收益均值,可以理解为前面算法说的点击率
- 核心是第二项,我们知道当x取值大于1时ln函数的作用是平滑,如果实验次数很多,那么后一项就会趋近很小,从而收敛到前一项收益均值,如果是一个新物料或者explor次数很少,那么后一项很大甚至大于1从而优先进行explor,支持探索到这个臂到达置信的次数。
- UCB就解决了前面汤普森采样人工先验设置参数以及探索到多少更置信的问题。
Epsilon-Greedy 算法
- 选一个 (0,1) 之间较小的数作为 epsilon
- 每次以概率 epsilon 做一件事:所有臂中随机选一个
- 每次以概率 1-epsilon 选择截止到当前,平均收益最大的那个臂。
这个算法中重要点的理解:
- 算法中需要调的参数比较多,比如epsilon控制explor比例,还有对于一个物品探索到那个界限K才会让利用起来比较置信
- 当然好处就是如果点击和展示结果不是实时能拿到的,那么最好的选择就是这个算法。
总结
有人做过实验,通过10000轮的实验得到每个算法的累积遗憾,结果是UCB算法和Thompson明显更优秀
累积遗憾的定义,其中\(w_{B{i}}\)是第i次实验选中臂的期望收益,\(w_{opt}\)是选中最佳的收益:
\[R_T = \sum_{i=1}^{T}(w_opt - w_{B(i)})\]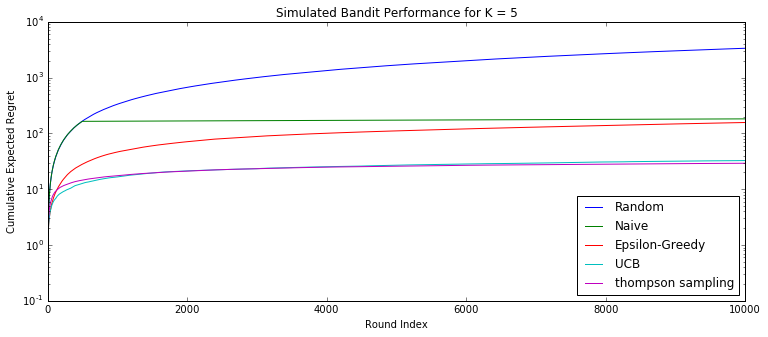
最后想说很多公司都不敢做EE,或者说不敢放开手做EE,毕竟一下子给用户推荐出去一堆的新物料可能会导致这个用户马上流失,但是我们通过实验发现恰恰这时候需要做EE,因为真实的推荐系统中,讲究一个生态的概念,生态是什么,就是物料要流动出去,每天把新的高质量的流进来,然后历史遗留的末尾的淘汰出去,用户产生更好更高质量的行为数据,喂给算法,那么这将是一个正向的生态,一个好的生态。
尤其是现在的短视频推荐,我们每天刷的抖音,其核心算法就是EE,不是什么高大上的算法。我们做过实验,做短视频推荐,如果你能把EE做完美了,那么你的算法效果至少能达到抖音的70%。
当然EE也有套路,对于不敢放开手EE,这里有两种思路:
- 不是所有人群的所有访问都适合做R。但是和传统的E & E不同的是,做“反向E & E”。也就是说,我们只针对非常Engaged的人做Exploration,而并不是新用户或者是还没有那么Engaged的人群。这个思路是和现在E & E完全相反,但是更加人性化。
- 夹带“私货”。也就是更改E & E的算法,使得高质量的内容和低质量的内容能够相伴产生,并且高质量的内容更有几率排在前面。这样用户体验的损失可控。这个思路我们有所尝试,效果不错。