做推荐系统将进两年了,最近闲下来总结自己做的一些事情,忽然想到一个问题,推荐系统的核心是什么?怎样推荐系统是一个业界比较先进的推荐系统?
推荐系统本质
首先我们来看第一个问题,推荐到底是在做一件什么事情。
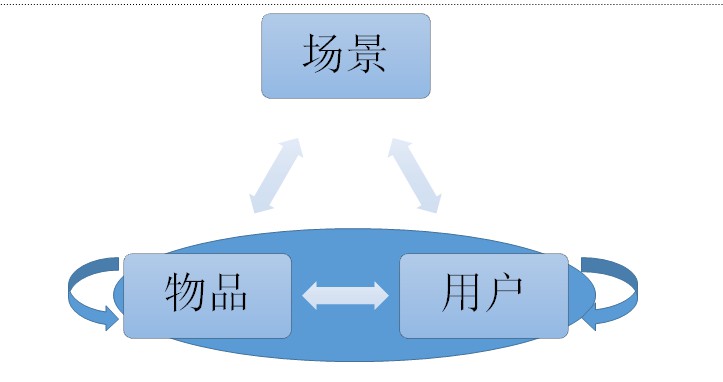
如上图所示,推荐本质上做的事情是用户(User)在某一场景或者环境(Scene)下,看到了自己最感兴趣的物品(Item)。例如音乐推荐,我在下午写代码的时候想听一些民谣或者好听的歌曲,晚上睡觉前想听一些轻音乐。事实上所有的推荐问题都围绕这三个点以及他们之间的关系上做文章,既然这三个点很重要那么首先想到的是要怎么定义他们。
首先要推荐物品,我们就要描述物品,这里可以叫物品模型,我们以音乐为例子
- 音乐信息基础特征
- 演唱者
- 演唱者性别
- 语言
- 作词作曲者
- 发行地区
- 发行时间(老歌/新歌)
- 音频特征
- 风格(民谣/摇滚/说唱)
- 情绪(激动/轻松/失望)
- 节奏(快/慢/中)
- 场景(散步/聚会/阅读/户外)
- 行为相关特征
- 全局热度
- 分类热度
- 主题热度
定义用户一般是用用户模型,其中常见的包含这些点:
- 身份特征
- 性别
- 年龄
- 常驻地
- 兴趣特征
- 物品相关的特征属性类
场景特征一般包括
- 时间
- ios/android
- 场景预测
- 天气(下雨/晴天/阴天)
- 位置(家/出差/公司)
事实上以上这些其实就是所谓的特征,一般通常会有一个体系,它是一个推荐系统的基石,如果特征抽取的准确,并且所有特征能够完全表示物品,那么已经成功了一半。 这其中包含一些难点,比如音频特征的提取,场景预测等
如果上面我们都能够描述清楚了,接下来的事情就是围绕着它们做一些事情了。
物品关联
怎么做事情呢,这其中很大一块儿是物品,而挖掘物品之间的关联关系又是里面很重要的一块,在音乐方面就是常说的相似歌曲。为什么说是很重要?
首先它本身就可以是一个产品,音乐上相似歌曲,资讯方面是关联资讯,除了这个之外还可以直接拿来推荐啊,给你个性化推荐歌曲,我可以直接拿你听过的收藏过得下载过得歌曲的相似歌曲推荐给你,做起来即简单又灵活。
那么怎么计算物品间关联关系呢,很简单,比如根据行为的方法,矩阵分解SVD,Item_CF,关联挖掘Apriori,或者直接基于内容计算相似度,在资讯这种时效性要求高的一般内容的方法用的比较多
除了挖掘关系之外,另一个本身质量要高,比如做音乐,没有版权,本有歌曲,推荐做出花儿来也没有用
用户关联
除了物品,另一个重要的就是用户。
推荐是机器学习的一个方向,本质是数据挖掘,而数据是用户产生的,也就是用户行为,说大一点就是生态,一个推荐主导的产品,用户生态非常重要,因为生态好意味这数据质量高,那么用一个很简单的算法就能产生很好的效果。比如网易云音乐的推荐大家都说好,其实不是技术多牛,而是生态好。
单独挖掘用户关联的相对物品关联比较少,但是几乎所有做推荐的都在做用户模型,即用一些特征去描述用户,个性化推荐,个性化中很重要的一环就是描述用户,千人千面中的千人必须描述清楚才能做到千面。
挖掘用户关联关系算法一般是User_CF,通常也是挖掘之后推荐相似用户喜欢的物品,本质上下面要说的用户-物品关联
用户-物品关联
早期的推荐系统基本上就是在挖掘用户-物品关联关系,比如最早的亚马逊的“购买了这个商品的用户也购买了”,“经常一起购买的商品”,本质上对应的就是User_CF,Item_CF
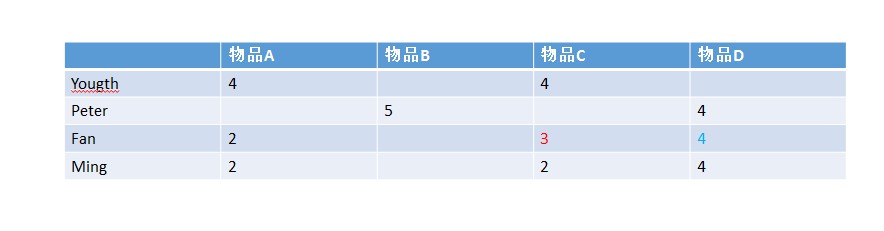
事实上只看用户和物品的关系的话,简单可以理解为这样一个矩阵的填充问题,这也是早期推荐研究的问题
User_CF本身是找那些用户购买的东西重合度很高,即相似用户簇,比如上面物品推荐,Fan和Ming对物品A和物品C的评分基本一致,而Ming喜欢物品D,那么我认为Fan也可能会喜欢物品D,我预测Fan对物品D的评分为4
Iter_CF是在找容易被一起购买的东西,即相似物品簇,比如上面物品A和物品C所有用户的评分一致型很高,那么我认为Fan对物品C的评分可能是3,当然也可能是2
后续发展出来了矩阵奇异值分解,在NetFlix比赛中Koren大神的SVD获得了冠军,受到了工业界的重视,其主要思想是把一个稀疏矩阵分解成两个稠密矩阵,然后找相似关系,假如上面是用户对音乐的评分的话,假如奇异值分解之后发现用户喜欢一个音乐只跟风格有关,两个奇异值分别是摇滚和民谣,也可以叫做隐特征,那么就分解成4×2的用户奇异值矩阵和2×4的物品奇异值矩阵,分解后的矩阵意义是用户对两个隐特征的喜好以及这四首歌曲中包含这两个隐式特征的程度。有了分解之后我们就可以计算相似物品了,或者直接通过矩阵相乘还原矩阵填充矩阵做推荐。
事实上直接分解的化效果不好,一般用的是SVD++,加入了隐式反馈,把原始数据直接输入矩阵,经验证效果很不错。
SVD好用的另一个原因是,工业上用户-物品矩阵通常非常稀疏,比如用户-音乐,音乐通常几千万,但是正常用户听歌几百首就很不错了,而通过矩阵分解之后两个矩阵就好多了。
另外还有基于内容的,资讯类的很多都是基于内容的算法,常用的主题模型Lsi算法,即抽取文章的主题,然后相同主题的聚类,或者直接把用户模型和文章放到一起提取主题,然后求用户和文章的相似度,本质上也是在填充上面的用户物品矩阵,只是基于内容的有好处就是不需要行为数据,所以能很好的解决冷启动问题,对是实行性要求高的效果很好。
场景-物品
做到后面大家发现场景也是推荐系统很重要的一环,那么怎么运用进去呢,就有了场景和物品的结合,典型的产品就是场景电台,例如跑步/工作/运动/在路上,这些简单的做法就是编辑把歌曲做好放到一个池子中,或者通过音频挖掘把歌曲特征得到,然后每个场景都有自己的歌曲池,然后通过简单的协同过滤或者随机出歌曲。
更智能的做法是通过app收集数据去分析场景,比如gps检测到在跑步或者开车,根据时间晚上预测以及根据天气取预测。
用户-场景-物品
事实上发展到现在,或者通过上面分析,我们发现推荐系统的本身是用户在某个场景下,看到自己最喜欢的物品。这其中每一环都不能少,于是发展出来了一环重排序层,并且作为推荐系统的核心,正真的千人千面,具体是怎么做的呢?
之前推荐一般的方法是类似搜索的召回机制,可以用下面这些召回
- 之前喜好物品的相似物品,收藏的歌曲相似歌曲
- 用户模型中各种特征下歌曲,比如用户特别喜好民谣
- 场景关联歌曲,比如下雨可能更喜欢听安静的歌曲
- 实时热点歌曲
这一步是找用户可能会喜欢的物品,只要是有可能喜欢的都可以假如召回机制,然后对于一个用户可能会召回很多歌曲
有了这一堆歌曲,但是我真正推荐给用户的物品只有有限个,那么我需要决定把那些物品推荐给用户,这里就加入了一个重排序机制,这其实是借鉴广告ctr预估做的,因为广告本质也是用户在某个场景最想点击的广告。
怎么做重排序呢,本质是个经典的监督学习问题,二分类问题,\(y = F(X_i ,X_u ,X_c)\)
简单的训练一个LR模型,把用户特征,物品特征,场景特征全部放进去,然后训练好了之后去重排序。
或者复杂的GBDT,Factorization Machine,深度学习DNN都可以,事实场这一步是很重要的一步,本质决定了推荐的效果。
好的推荐系统
上面推荐本质做好基本上就已经很不错了,要做到不断完善,另外两个方面不能忽略。
一个是abtest,能够简单的隔离分桶对算法做实验。
另一个是推荐评价指标系统,能够实时看到线上推荐的表现,最好是能够对abtest通过指标对比给出报告。
指标最好能够兼顾短期指标和长期指标,同时兼顾用户指标和生态指标,即保证物品的质量同时尽可能满足用户需求