机器学习系列基础算法,支持向量机
定义问题
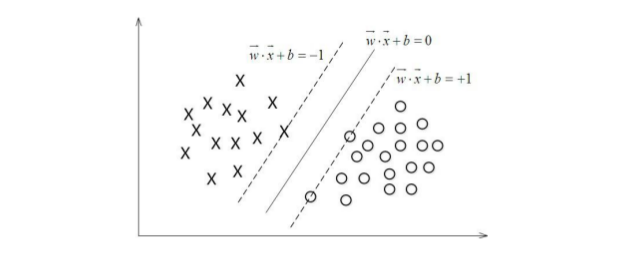
这里的问题也是一个二分类问题,比如最简单的要把图上的两种类型的点区分开,我们定义分类函数为\(f(x)=w^Tx+b\),当\(f(x)=0\)时就是位于平面上的分隔线,而\(f(x)>0\)对应于\(y=1\)的点, \(f(x)<0\)的点对应于\(y=-1\),如下图所示。
间隔函数
那么要怎么分类才算是好的呢?之前在逻辑回归中,我们用一个logistic函数,把线性函数值y映射到\((0-1)\)区间,然后根据映射后的值跟区间中值0.5的大小确定分类。
这里我们运用另一种思路,对于上面的平面,我们尝试去找到一条直线,那么如果把这条直线按照斜率相等平移,必然在上方和下方都能找到一个最近的相交点,如上图所示,支持向量机的思路就是找到这样一条直线,使得和上下相交的点的两条直线的间隔最大。
在平面\(w^T+b=0\)确定的情况下,|\(w^T+b\)|可以相对的表示点\(x\)距离平面的距离,如果\(w^T+b>0\)则表示当前类别为\(+1\),而且其值得大小表示分类结果的置信的度,反之也是,这里\(w^T+b\)称为函数间隔。
我们很容易发现一个问题,就是\(w\)和\(b\)如果同时成倍数增加的话,函数间隔的结果没有影响,但是很明显函数的间隔大小变化了,所以需要把\(w\)固定下来,我们用范数\(\|w\|\)来表示,其实就是平方和,那么几何间隔
\[r= \frac{w^x+b}{||w||}= \frac{f(x)}{||w||}\]其实我们发现就是几何距离,在二维情况下就是点到直线距离。
为了得到\(r\)的绝对值,我们乘上它的类别\(y\),负负相互抵消则几何距离\(\widetilde r=yr= \frac{\hat r}{\|w\|}\)
最大间隔
定义要求解的最大间隔\(max \ \widetilde r\),而\(y_i(w^T+b)= \widetilde r_i \ge \widetilde r, i=1,....,n\),这个约束条件因为所有几何间隔都比当前距离远,当前就是我们最大间隔的边界,如上面图。
如果我们令函数间隔\(\hat r = 1\),则几何间隔\(\widetilde r = \frac{1}{\|w\|}\),目标函数转化为
\[max \frac {1}{||w||}, st. y_i(w^Tx_i+b) \ge 1, i=1,.....,n\]我们变化一下为求解最小值
\[min \frac {1}{2}{||w||^2}, st. y_i(w^Tx_i+b) \ge 1, i=1,.....,n \tag {3.0}\]注意这里加入\(\frac{1}{2}\)和平方纯粹是为了后面求导数方便,没有任何其他函数,上下两个问题是等价的。
定义凸二次规划
这儿的问题就是一个传说中的凸二次规划问题,凸含义就是可以理解为\(x^2\)这个函数的图像,是个凸的,而二次规划,规划数学上求解最优化目标都叫规划问题,这里二次规划就是带一定约束条件的求解最优化问题。
二次规划可以用传说中的拉格朗日法,定义拉格朗日函数
\[\mathcal{L}(w,b,\alpha)=\frac{1}{2}||w||^2- \sum_{i=1}^n \alpha_i(y_i(w^Tx_i+b)-1) \tag{4.0}\]然后令
\[\theta (w)=\mathop{max}_{ {\alpha_i \ge0}} \mathcal{L}(w,b,\alpha)\]根据拉格朗日定义,目标函数变成
\[\mathop{min}_{w,b} \theta(w)=\mathop{min}_{w,b} \mathop{max}_{\alpha_i \ge0} \mathcal{L}(w,b,\alpha)=p^* \tag{4.1}\]转化到这儿,其实看到本身还是在求上面3.0,因为4.0后半部分如果有点划分错误,即\(y_i(w^Tx_i+b) < 1\),而\(\alpha\)为无穷大时,整个\(\mathcal{L}(w,b,\alpha)\)变成无穷大,没有意义了,所以只有满足约束条件时候才有意义,相当于转化变成可求解的形式。
我们转化为求解对偶问题
\[\mathop{max}_{\alpha_i \ge0} \mathop{min}_{w,b} \mathcal{L}(w,b,\alpha)=d^* \tag{4.2}\]上面两个公式满足\(d^* \le p^*\)必须在满足KKT条件下才成立,互为充要条件。
求解对偶问题
我们先求解第一个最小值,固定\(\alpha_i\)当作已知量,通过求导
\[\frac {\partial \mathcal{L}}{\partial{w}} = w - \sum_{i=1}^n(\alpha_ix_iy_i) = 0\] \[\frac{\partial \mathcal{L}}{\partial b} = \sum_{i=1}^n(\alpha_iy_i)=0\]求解得到
\[w=\sum_{i=1}^n{\alpha_ix_iy_i}\]带入到拉格朗日函数
\[\begin{eqnarray*} \mathcal{L}(w,b,\alpha) & = & \frac{1}{2}w^Tw-\sum_{i=1}^n\alpha_i y_i w^Tx_i - \sum_{i=1}^n\alpha_i y_i b + \sum_{i=1}^n\alpha_i \\ & = & \frac{1}{2}w^T\sum_{i=1}^n \alpha_i x_i y_i - w^T \sum_{i=1}^n \alpha_i y_i x_i - \sum_{i=1}^n \alpha_i y_i b + \sum_{i=1}^n \alpha_i \\ & = & -\frac{1}{2}w^T \sum_{i=1}^n \alpha_i x_i y_i - b \sum_{i=1}^n \alpha_i y_i + \sum_{i=1}^n \alpha_i \\ & = & \sum_{i=1}^n \alpha_i - \frac {1}{2} \sum_{i=1,j=1}^n \alpha_i \alpha_j y_i y_j x_i^T x_j \end{eqnarray*}\]这样就只剩下关于拉格朗日乘子\(\alpha\)相关的目标函数了,剩下就是求解
\[\mathop{max}_{\alpha_i \ge0} \sum_{i=1}^n \alpha_i - \frac {1}{2} \sum_{i=1,j=1}^n \alpha_i \alpha_j y_i y_j x_i^T x_j\] \[st. \alpha_i \ge 0 \ \ \ \ \ \sum_{i=1}^n \alpha_i y_i = 0\]核函数
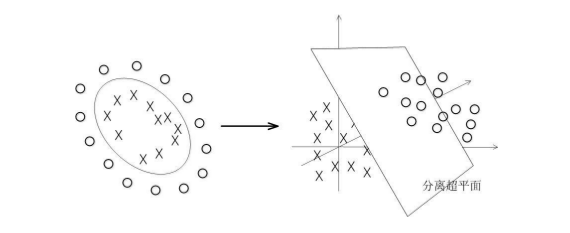
我们上面讨论的,是用一个超平面去划分空间,,比如是n维的空间,我们就用n-1维的超平面去划分,前提条件是这个模型是可以线性分开的,但是现实中的很多问题往往不是线性能区分的,比如下图中的圈和x,很明显不能用直线去划分,但是我们仍然能够想办法划分,这也是svm被称为最好的分类器的原因。
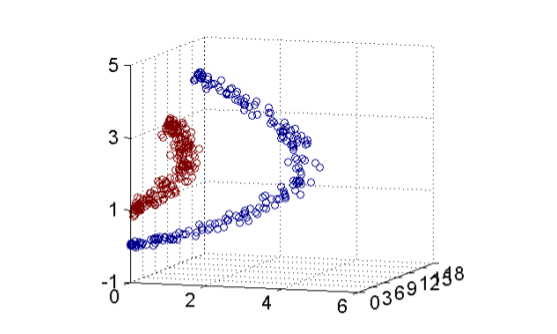
事实上上面划分曲线是一个非线性的圆,圆的一般方程是\((x_1-a)^2+(x_2-b)^2=r\),我们假设在一个坐标轴上的圆\((x_1-a)^2+x_2^2 = r\) ,展开之后就是\(x_1^2 - 2ax_1+a^2 + x_2^2=r\),抛开\(a,r\)这类参数,原来的x变成了除了\(x\)还有\(x^2\),如果我们用\(z_1=x_1^2\),那么上面等式变成
\[z_1+x_2^2-2ax_1=r-a^2\]变成了一个三维空间的线性方程,三维我们就可以画图看了,坐标轴上的圆划分映射到三维之后大概是这样子,可以用平面划分了。
我们刚开始定义的划分超平面
\[y = w^Tx + b\]从矩阵形式转化到一般的形式
\[f(x) = \sum_{i=1}^n w_i x_i + b\]对于上面问题,我们对\(x_i\)做了特征映射,映射到高维度空间,这里用\(\phi\)表示空间映射
\[f(x) = \sum_{i=1}^n w_i \phi_i(x) +b\]带入前面求导得到的\(w = f(x) = \sum_{i=1}^n \alpha_i x_i y_i\),得到:
\[f(x) = \sum_{i=1}^n \alpha_i y_i \langle \phi(x_i),\phi(x) \rangle + b\]这里的空间映射通用的表示可以用特征\(x_i\)间的内积表示,考虑如果到所有特征关系的情况,比如有两个特征\(x1,x2\),所有映射情况可以用\((x_1+x_2+b)^d\)表示。本质上可以用考虑所有特征关联的情况,比如我们根据父母身高体重取预测孩子身高体重,不止单独考虑各自身高,体重,考虑到身高和体重的关系是否会对结果更好。
对应到目标函数上,目标函数为
\[\mathop{max}_{\alpha_i \ge0} \sum_{i=1}^n \alpha_i - \frac {1}{2} \sum_{i=1,j=1}^n \alpha_i \alpha_j y_i y_j \langle \phi(x_i), \phi(x_j) \rangle\] \[st. \alpha_i \ge 0 ,ii=1,......,n\ \ \ \ \ \sum_{i=1}^n \alpha_i y_i = 0\]核函数的厉害之处在于把低维空间转化为高维空间,它通过事先在低维上计算,而实质的分类效果表现在高维上,避免了直接在高维上的计算。
另一个问题就是特征映射到高维度一定线性可分吗,查了一下说无噪声的数据理论上存在一个核函数,使得映射后的数据线性可分,但是目前没有人能够证明。运用最多的高斯核,实际上只是提高了线性可分的概率,就是说用高斯核比不用效果好。
核函数这快水挺深的,研究研究可以单独开一篇,常用的核函数有多项式核,比如上面这个问题就是多项式核
\[K(x_1,x_2) = (\langle x_1,x_2 \rangle + R)^d\]高斯核
\[K(x_1,x_2) = exp(\frac{-||x_1 - x_2||^2}{2 \sigma^2})\]SMO算法
序列最小最优化算法(SMO)是一种启发式算法,意思就是通过一个不稳定的执行,得到一个比较优的结果。原理是如果所有变量都满足最优化问题的KKT条件了,那么就认为当前是最优解,因为KKT条件是最优解的充分必要条件。
如果当前拉格朗日乘子\(\alpha\)中有不满足KKT条件的,那么我们就选择两个\((\alpha_1, \alpha_2)\),其中一个就是前面不满足KKT条件的,其他的乘子都是固定的,即已知变量。那么目标函数写成求最小值的形式,带入得到
\[\mathop{min}_{\alpha_1, \alpha_2} W(\alpha_1,\alpha_2) = \frac{1}{2} K_{11} \alpha_1^2 + \frac{1}{2} K_{22} \alpha_2^2 + y_1 y_2 K_{12} \alpha_1 \alpha_2 + y_1 \alpha_1 \sum_{i=3}^n y_i \alpha_i K_{1i} \\ + y_2 \alpha_2 \sum_{i=3}^n y_i \alpha_i K_{2i} - (\alpha_1+ \alpha_2) \tag{6.1}\] \[st \ \ \ \ \alpha_1 y_1 + \alpha_2 y_2 = - \sum_{i=3}^n y_i \alpha_i = \zeta \tag{6.0}\] \[0 \le \alpha_i \le C \ \ \ \ i=1,2 \tag{6.2}\]上式中的\(K_{ij} = K(x_i, x_j)=\phi(x_i, x_j),i,j=1,2,.....,N\), \(\zeta\)是个常数项
这里的第二个约束条件C是正则化项的系数,和逻辑回归一样,这个约束条件也是最正则化项求导得到的
式6.0因为y的取值是1或者-1,那么等式基本上就是\(\alpha_1+\alpha_2=k\)或者\(\alpha_1-\alpha_2=k\),假设刚开始两个解为 \(\alpha_1^{old}, \alpha_2^{old}\),最优解为 \(\alpha_1^{new}, \alpha_2^{new}\),沿着约束方向未经剪辑时候\(\alpha_2\)的最优解为\(\alpha_2^{new,unc}\)
我们假设对\(\alpha_2^{new}\)有以下约束,假设它的上界和下界分别是L和H
\[L \le \alpha_2^{new} \le H\]由公式 6.0 ,我们假设\(y_1 \not= y_2\),则\(\alpha_1^{old} - \alpha_2^{old} = \zeta\)
\[L = max(0, \alpha_2^{old}-\alpha_1^{old}) \ \ \ H=min(C,C+\alpha_2^{old}-\alpha_1^{old}) \ \ \ \ \ if (y_1 \not =y_2)\]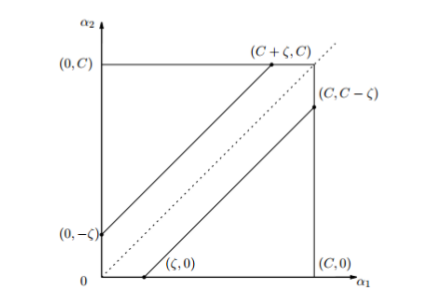
同样由公式 6.0 ,我们假设\(y_1 = y_2\),则\(\alpha_1^{old} + \alpha_2^{old} = \zeta\)
\[L = max(0, \alpha_2^{old}+\alpha_1^{old}-C) \ \ \ H=min(C,\alpha_2^{old}+\alpha_1^{old}) \ \ \ \ \ if (y_1 =y_2)\]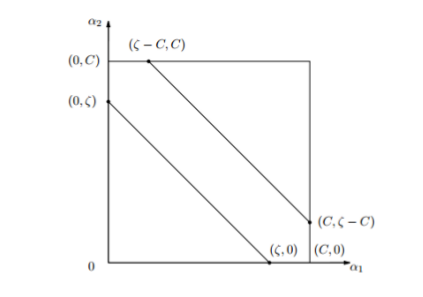
前面
\[f(x) = \sum_{i=1}^n \alpha_i y_i \langle \phi(x_i),\phi(x) \rangle + b\]定义损失函数,评估预测准确性
\[E_i=g(x_i)-y_i =\sum_{i=1}^n \alpha_i y_i \langle \phi(x_i),\phi(x) \rangle + b -y_i, \ \ \ \ i=1,2\]通过对式6.0两边同时乘以\(y_1\)得到
\[\alpha_1^{old}+(y_1 y_2)\alpha_2^{old} = \alpha_1^{new}+(y_1 y_2)\alpha_2^{new} = -y_1 \sum_{i=3}^n y_i \alpha_i\] \[\alpha_1^{new}=\alpha_1^{old} + y_1 y_2(\alpha_2^{old} - \alpha_2^{new}) \tag{6.3}\]而把上式变化得到\(\alpha_1^{old} = -y_1 \sum_{i=3}^n y_i \alpha_i - y_1 y_2 \alpha_2^{old}\)带入式6.1,变成只有\(\alpha_2^{old}\)一个参数的函数,求导令导函数等于0,得到
\[\alpha_2^{new,unc} = \alpha_2^{old} + \frac{y_2(E_1-E_2)}{\eta}\]其中
\[\eta = K_{11}+K_{22} -2K_{12} = ||\phi(x_1)-\phi(x_2)||^2\]则剪辑之后\(\alpha_2^{new}\)的解为
\[\alpha_2^{new} = \left\{ \begin{aligned} H & , & \ \ \ \ \alpha_2^{new,unc} > H \\ \alpha_2^{new,unc} & , & \ \ \ L \le \alpha_2^{new,unc} \le H \\ L & , & \ \ \ \alpha_2^{new,unc}< L \end{aligned} \right.\]这里我们由公式 6.2 条件可知,\(\alpha_2\)的取值不止是L和H,但是我们前面已经得到约束条件了,L和H是更强的约束条件,更容易得到最优解
然后带入6.3,求解出\(\alpha_1^{new}\)就完了。
这里第一个变量\(\alpha_1\)的选择是违反KKT(式6.2)最严重的样本点,第二个变量选择目标是使得\(\alpha_1\)的变化尽量大,就是|\(E_1-E_2\)|最大,如果一直不能优化当前\(\alpha_1\)的话,可以考虑随机选择。
而\(b\)满足下面条件:
\[b = \left\{ \begin{aligned} b_1 & , & \ \ \ \ 0<\alpha_1^{new}<C \\ b_2 & , & \ \ 0<\alpha_2^{new}<C \\ \frac{b_1+b_2}{2} & , & \ \ \ otherwise \end{aligned} \right.\]更新b
\[b_1^{new} = b^{old} - E_1- y_1(\alpha_1^{new}-\alpha_1^{old})K(x_1,x_1) - y_2(\alpha_2^{new}-\alpha_2^{old})K(x_1,x_2)\] \[b_2^{new} = b^{old} - E_2- y_1(\alpha_1^{new}-\alpha_1^{old})K(x_1,x_2) - y_2(\alpha_2^{new}-\alpha_2^{old})K(x_2,x_2)\]这里b的更新是那个满足KKT条件就按照那个,如果两个都不满足就取中值然后等待下一轮计算,求 \(b_1,b_2\) 的公式是根据直线方程前后相等推导出来的。
总结
支持向量机优缺点
优点
- 可以解决高维问题,即大型特征空间;
- 能够处理非线性特征的相互作用;
- 无需依赖整个数据;
- 可以提高泛化能力;
缺点
- 当观测样本很多时,效率并不是很高;
- 对非线性问题没有通用解决方案,有时候很难找到一个合适的核函数;
- 对缺失数据敏感;
这个算法基本上是十大经典算法中最难啃的一个了,基本上大多数都是参考支持向量机通俗导论,还有《统计学习方法》,两个都是经典中的经典。
代码实现
我们来看一个机器学习实战上面的代码来做数字识别,证明它确实是最好的单模型分类算法,算法中的数据同时来自书上的,这里可以下载,用的核函数是高斯核函数,尝试不同的 \(\sigma\) 值,在值为10时候效果最好,结果大概是这样,128个支持向量,训练错误率为0,测试错误率0.005,基本上很优秀了,不但结果好,而且效率高,可以尝试不同的 \(\sigma\),同时还提供了线性核函数,也可以试试。
iteration number: 6
there are 128 Support Vectors
the training error rate is: 0.000000
the test error rate is: 0.005376
代码
'''
Created on Nov 4, 2010
Chapter 5 source file for Machine Learing in Action
@author: Peter
'''
from numpy import *
from time import sleep
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])#if checks if an example violates KKT conditions
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m)
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print "L==H"; continue
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print "eta>=0"; continue
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])#update i by the same amount as j
#the update is in the oppostie direction
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1
print "iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print "iteration number: %d" % iter
return b,alphas
def kernelTrans(X, A, kTup): #calc the kernel or transform data to a higher dimensional space
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #linear kernel
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
else: raise NameError('Houston We Have a Problem -- \
That Kernel is not recognized')
return K
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEk(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJ(i, oS, Ei): #this is the second choice -heurstic, and calcs Ej
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei] #set valid #choose the alpha that gives the maximum delta E
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #don't calc for i, waste of time
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k):#after any alpha has changed update the new value in the cache
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerL(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #changed for kernel
if eta >= 0: print "eta>=0"; return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas
def calcWs(alphas,dataArr,classLabels):
X = mat(dataArr); labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i],X[i,:].T)
return w
def testRbf(k1=1.3):
dataArr,labelArr = loadDataSet('testSetRBF.txt')
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', k1)) #C=200 important
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd] #get matrix of only support vectors
labelSV = labelMat[svInd];
print "there are %d Support Vectors" % shape(sVs)[0]
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the training error rate is: %f" % (float(errorCount)/m)
dataArr,labelArr = loadDataSet('testSetRBF2.txt')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the test error rate is: %f" % (float(errorCount)/m)
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def loadImages(dirName):
from os import listdir
hwLabels = []
trainingFileList = listdir(dirName) #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
if classNumStr == 9: hwLabels.append(-1)
else: hwLabels.append(1)
trainingMat[i,:] = img2vector('%s/%s' % (dirName, fileNameStr))
return trainingMat, hwLabels
def testDigits(kTup=('rbf', 10)):
dataArr,labelArr = loadImages('trainingDigits')
print dataArr[0],labelArr
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, kTup)
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd]
labelSV = labelMat[svInd];
print "there are %d Support Vectors" % shape(sVs)[0]
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the training error rate is: %f" % (float(errorCount)/m)
dataArr,labelArr = loadImages('testDigits')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the test error rate is: %f" % (float(errorCount)/m)
'''#######********************************
Non-Kernel VErsions below
'''#######********************************
class optStructK:
def __init__(self,dataMatIn, classLabels, C, toler): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
def calcEkK(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*(oS.X*oS.X[k,:].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJK(i, oS, Ei): #this is the second choice -heurstic, and calcs Ej
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei] #set valid #choose the alpha that gives the maximum delta E
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #don't calc for i, waste of time
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEkK(oS, k):#after any alpha has changed update the new value in the cache
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerLK(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0
eta = 2.0 * oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T - oS.X[j,:]*oS.X[j,:].T
if eta >= 0: print "eta>=0"; return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
def smoPK(dataMatIn, classLabels, C, toler, maxIter): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas
if __name__ == '__main__':
#dataArr, labelArr = loadDataSet('testSet.txt')
#a, alphas = smoSimple(dataArr, labelArr, 0.6, 0.001, 40)
#a, alphas = smoP(dataArr, labelArr, 0.6, 0.001, 40)
#print a
#print alphas
#testRbf(0.1)
testDigits() #judge whether it is 9