召回
相关指标
- 曝光vv占比、曝光uv占比、独特率、独特数、后验(短视频有效播放、完播率、播放完成度;点击场景ctr、uv-ctr)
- 漏斗指标,用于排查问题和优化:各层占比、通过率、独特率、用户渗透
模型召回
多目标双塔
正样本(对齐下游目标):
- 有效播放:(播放时长≥5s且视频时长<20s)or(播放时长 ≥7s且视频时长≥20s)
- 长播放:播放时长≥30s
- 高完播:根据视频时长划分计算播放率,大于0.8为高完播
- 转化:完播(播时 >= 视频时长)、 (长播)播时>30s 、 关注 、 点赞 、 分享
负样本:
- 全局负采样5+曝光负样本1+batch内负样本*250
- 负样本生成逻辑:每条正样本从当天曝光池中随机采样5条负样本(至少一个目标为正),并且采样1条这个用户的曝光负样本(全部目标为负)作为困难负样本
- batch内随机负采样(或者N-pair loss) ∑i=0n∑j=0nCELoss(sigmoid(simi,j),labeli,j)\sum_{i=0}^{n}\sum_{j=0}^{n}CELoss(sigmoid(sim_{i,j}),label_{i,j})\sum_{i=0}^{n}\sum_{j=0}^{n}CELoss(sigmoid(sim_{i,j}),label_{i,j})
模型: 双塔,user测用一个,item测4个,最终目标loss融合
优势: 占比高、透出率高
缺点: 头部item集中、样本复杂学习较困难
一致性双塔
正样本: 精排top100 || 关注 || 评论 || 点赞 || 浏览作者主页 || 浏览评论 || 分享 || 长播(播放时长大于30s)
负样本: bacth内30条 + hard5条
- 构造当天播放item_id+slot hash字典(全局采样)
- 在模型训练的自定义样本处理阶段对每条req_id+imei进行负采样处理。
- 根据当前req_id+imei,取当前item的品类,然后随机从上述字典里面采样1条品类相同item,5条其他的item(hard采样)
- 保留当前req_id+imei的user侧特征,拼接随机采样的item特征
- 生成6条新样本后组装batch,然后训练(batch内loss负采样仍然保留)
模型: 标准双塔,4层
优点: 增加不同tag1的采样能大幅提升召回率和vv占比。
缺点: 本身在框架内实现,效率低训练时间长。
兴趣召回mind
正样本: 有效播放
负样本: 曝光正样本 + 256batch内负样本 + 1:10全局随机负采样样本
模型:
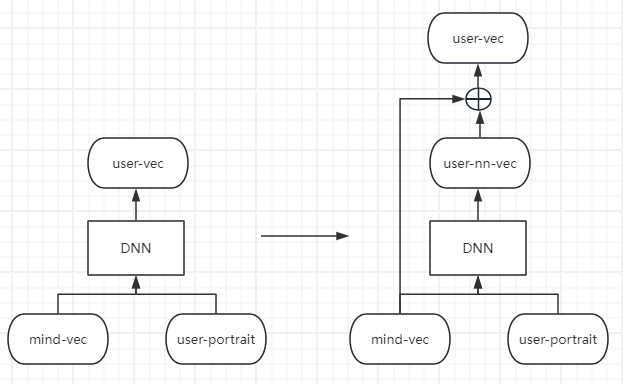
优点: 表达用户兴趣
缺点: 难表示兴趣迁移、以及召回池有限整体影响较小
功能双塔召回
主要两个方向,分人群召回和分内容属性召回。
分人群的比如中年女性之类的人群、新用户类、某种机型类。
分内容属性的比如新闻、影视、短剧之类。
主要方式就是搞一个专门内容池,然后用上面提到的主模型去做召回,服务专有人群或者某种内容的分发。
协同召回
icf
- 传统icf,公式简洁容易理解、线上表现不错、目前依然是主召回通道。
- 变种swing等,更偏向长尾和多样性,属于icf的补充。
- 模型icf学习,通过item双塔,icf的结果作为label学习,头部不如icf,但泛化和长尾效果好。
ucf
- 传统ucf,通过聚类等实现,通常效果不如icf
- 模型u2u2i,通过模型产出的user emb,拉取得相似用户在获得正向行为。效果不错,通常是核心召回通道。
倒排召回
兴趣召回
** 关注召回**
** 热点召回**
其他
- 基于用户画像/用户理解/内容属性偏好、长尾兴趣、潜在兴趣/探索、冷启召回
- 图神经网络、知识图谱(多样性、惊喜度)等